Kiến trúc của mô hình Llama

Giới thiệu
Xin chào mọi người, chắc phải gần một tháng từ khi có bài blog về LoRA và QLoRA, mình có khá lười viết các bài blog, tuy nhiên sắp tới mình sẽ cố gắng từ 1-2 tuần có một bài blog, hy vọng mọi người đón xem và góp ý. Tuần vừa qua, mình dành thời gian để tìm hiểu về các mô hình ngôn ngữ lớn (điều gì khiến chúng có khả năng tốt đến như vậy ?) Chúng phát triển như vậy có thể do dữ liệu chúng được học là rất lớn - nhưng làm sao chúng có thể học và học như thế nào từ “đống dữ liệu khổng lồ” đó. Câu hỏi này thôi thúc mình tìm hiểu và tất cả mọi thứ đều dẫn tới một kiến trúc mạng học sâu được gọi là Transformers. Tuy nhiên như tiêu đề của bài blog này, hôm nay chúng ta sẽ không nói về Transformers, mà thay vào đó, mình sẽ cùng tìm hiểu về kiến trúc của một mô hình khá nổi tiếng đó là mô hình Llama - kiến trúc dựa trên Transformers
Llama là gì ?
Llama (Large Language Model Meta AI) cũng giống như GPT, Gemini,.. nó là một mô hình ngôn ngữ lớn được phát triển bởi Facebook, điều làm nó trở nên phổ biến hơn trong cộng đồng nghiên cứu là do nó được open source và cho phép nhiều nhà khoa học có thể tiếp cận, fine tuning và nghiên cứu trên nó. Như đã đề cập ở trên, mô hình này dựa trên kiến trúc Transformer - chỉ lấy phần decoder tương tự như với GPT.
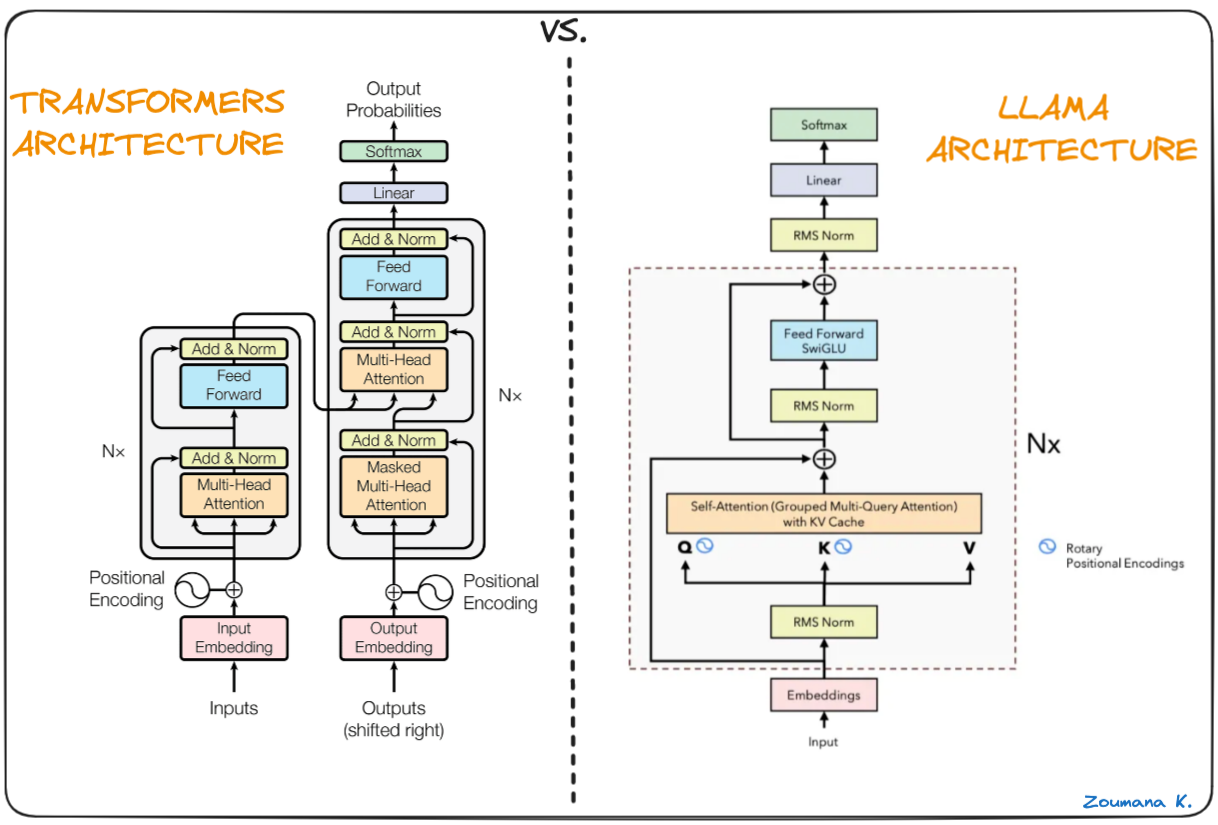
Về lịch sử một chút, mô hình này lần đầu tiên được công bố trong bài báo LLaMA: Open and Efficient Foundation Language Models của Meta AI vào đầu năm 2023. Điểm đặc biệt của mô hình này đó là nó được huấn luyện trên các bộ dữ liệu public và được open source - mọi người có thể dễ dàng sử dụng thông qua hugging face. Tiếp ngay sau đó, giữa 2023, mô hình Llama2 được ra đời với kiến trúc gần như tương tự nhưng được huấn luyện trên bộ dữ liệu lớn hơn. Ngoài ra, trong Llama2, một phiên bản Llama2-Chat cũng được giới thiệu với khả năng có thể so sánh được so với ChatGPT hay Gemini. Năm 2024, lần lượt các phiên bản Llama3, Llama3.1, Llama3.2 được ra đời, tuy nhiên, về mặt kiến trúc chúng không có quá nhiều thay đổi so với người tiền nghiệm. Để so sánh giữa các phiên bản của Llama, mình sẽ hẹn mọi người ở bài blog khác, còn trong bài blog này, mình xin tập trung khám phá kiến trúc đằng sau mô hình này.
Điều gì đằng sau Llama ?
Cũng giống với GPT, bản chất của Llama đó là học dựa trên các từ trước đó để dự đoán từ tiếp theo (hay nó còn được gọi là autoregressive model). Kiến trúc của mô hình này là biến thể của Transformers decoder-only, thay thế một số lớp trong mạng truyền thống này.
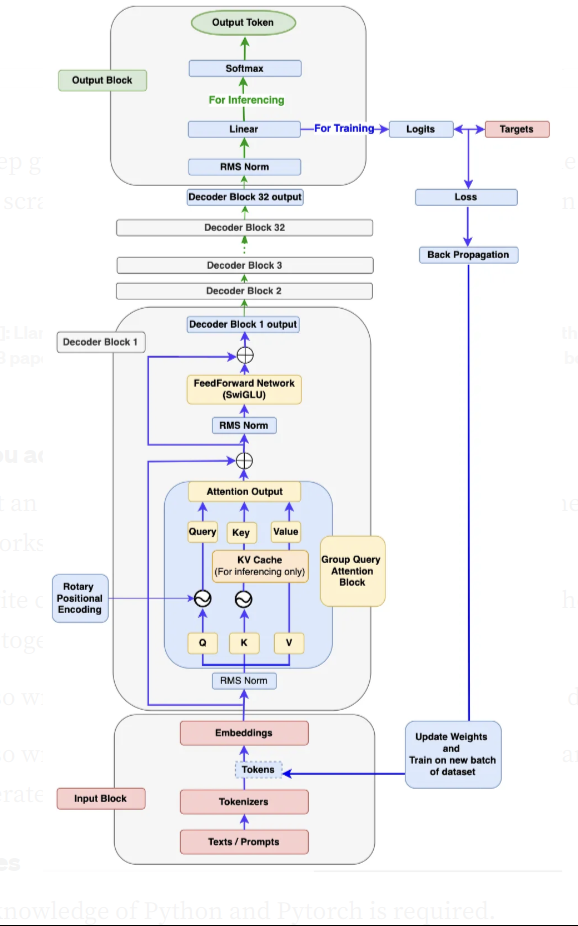
Cũng giống với các mô hình ngôn ngữ thông thường, mình sẽ chia nhỏ kiến trúc này thành 3 phần: Khối đầu vào (input), Khối đầu ra (output), Khối decoder. Tùy thuộc vào kích thước của từng biến thể mà số lượng lớp layer này được thay đổi, tuy nhiên, về cơ bản, chúng vẫn có cấu trúc dưới dạng 3 phần như trên. Để phân tích, mình sẽ sử dụng mô hình Llama3 - phiên bản mới nhất của Llama.
Khối Input
Tương tự như với lớp input của các mô hình ngôn ngữ khác, lớp này dùng để chuyển đổi các chuỗi text đầu vào thành các token và embeddings chúng chở thành các chuỗi số.
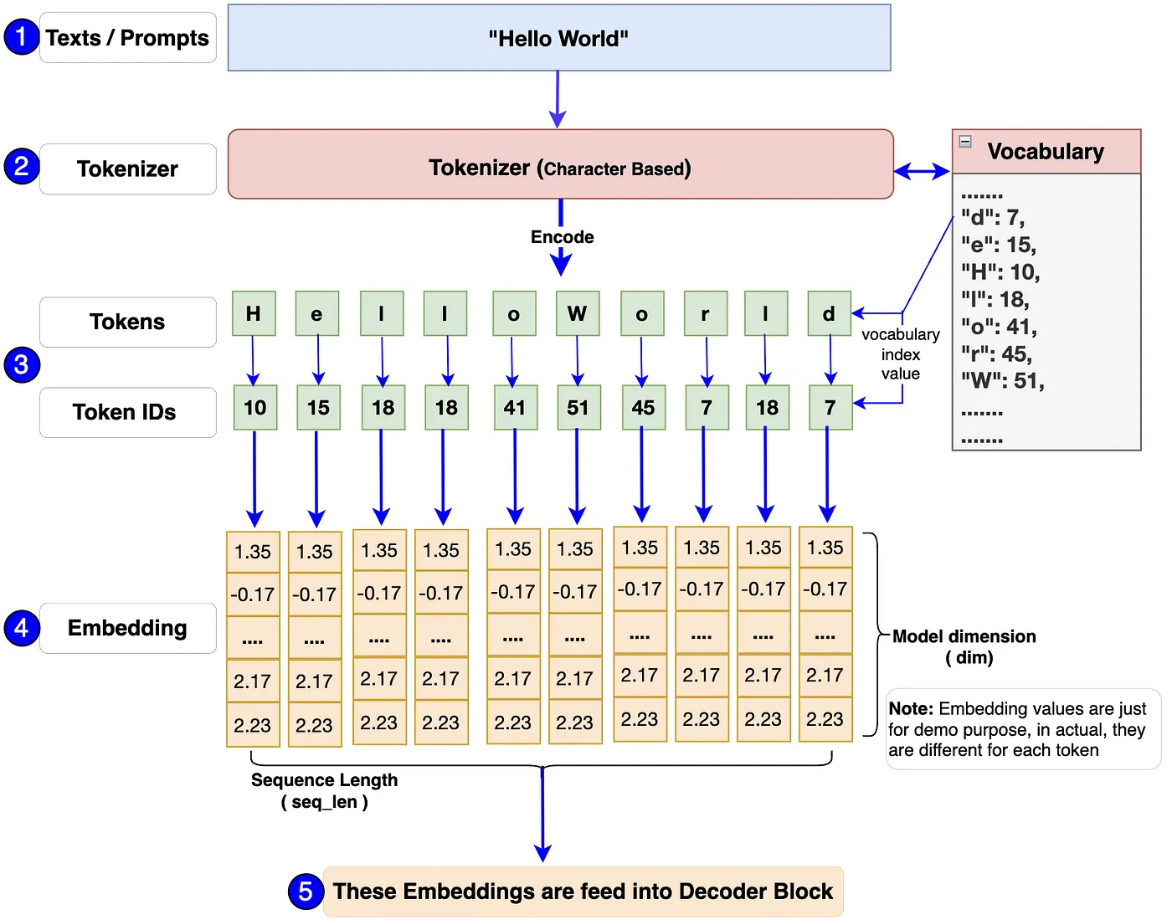
Dựa vào biểu đồ trên, bạn sẽ có hình dung rất rõ về quy trình hoàn thiện của bước này. Từ text đầu vào, nó được phân chia nhỏ thành các kí tự thông qua tokenizer, mỗi tokens này sẽ được mapping với chính ids của nó có trong bộ vocab được xây dựng sẵn. Các tokenizer này có thể là Tiktoken (Llama3) hoặc SentencesPiece(Llama1, 2). Mô hình embedding sẽ được huấn luyện để chuyển đổi các tokens ID trên thành các vector. Các vector này biểu diễn về mặt ngữ nghĩa và quan hệ giữa các từ.
Khối decoder
Đây cũng là điểm trọng tâm, cũng như khác biệt của Llama so với các mô hình khác. Dựa vào hình phía trên, cấu trúc của khối này được chia thành 5 phần nhỏ: RMS Norm, Rotary Positional Encoding, Group-query attention, KV Cache, FeedForward (SwiGLU).
RMS Norm
RMS Norm (Root Mean Square Normalization) được giới thiệu vào năm 2019 và được sử dụng trong nhiều mô hình ngôn ngữ thay thế cho LayerNorm thông thường. Theo nhóm tác giả, lựa chọn thay thế này được lấy cảm hứng từ phần pre-normalization của GPT3. Vậy ưu điểm của RMS Norm là gì?

Bản chất của lớp normalize đó là scale các điểm dữ liệu về một khoảng, một phân bố nhất định, làm giảm ảnh hướng của các điểm, giá trị lớn hơn nhiều so với các giá trị khác. Nó giúp mô hình tránh khỏi hiện tượng gradient vanishing, tối ưu tốc độ hội tụ của mô hình. Dựa vào công thức ở trên, có thể nhận thấy, việc tính toán của RMS nhanh hơn rất nhiều so với Layer Norm thông thường. Không cần tính toán giá trị mean hay std, thay vào đó, RMS sử dụng trung bình của tổng bình phương làm thành phần để chuẩn hóa. Nó giúp giảm thiểu 7-64% tốc độ tính toán của LayerNorm mà độ chính xác vẫn được đảm bảo
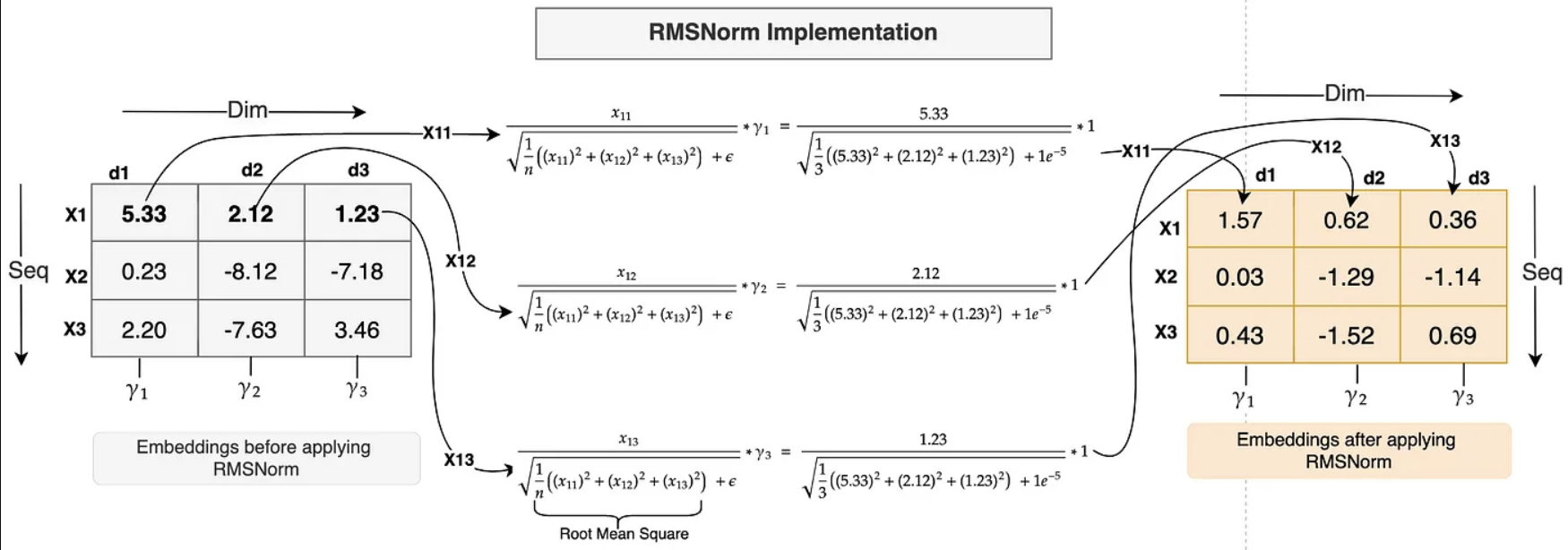
Lớp RMS Norm nhận đầu vào là chuỗi các emdbedding vector (đầu ra của input blocks), nó thực hiện tính toán và chuẩn hóa từng chiều của vector thông qua công thức trên với tham số học của lớp này là $\gamma $.
Rotary Positional Encoding (RoPE)
Theo nhóm tác giả, họ đã loại bỏ lớp absolute positional embedding trong Transformers và sử dụng RoPE thay thế, giống với mô hình GPTNeo. Cũng giống như các lớp positional encoding khác, lớp này dùng để lưu trữ thứ tự của các từ trong câu, vì sau quá trình embedding, gần như thứ tự của các từ trong câu đều có gía trị như nhau (“I love you” = “You love I”). Giống với chính tên gọi của nó, lớp này lưu trữ thông tin thông qua phép xoay vector
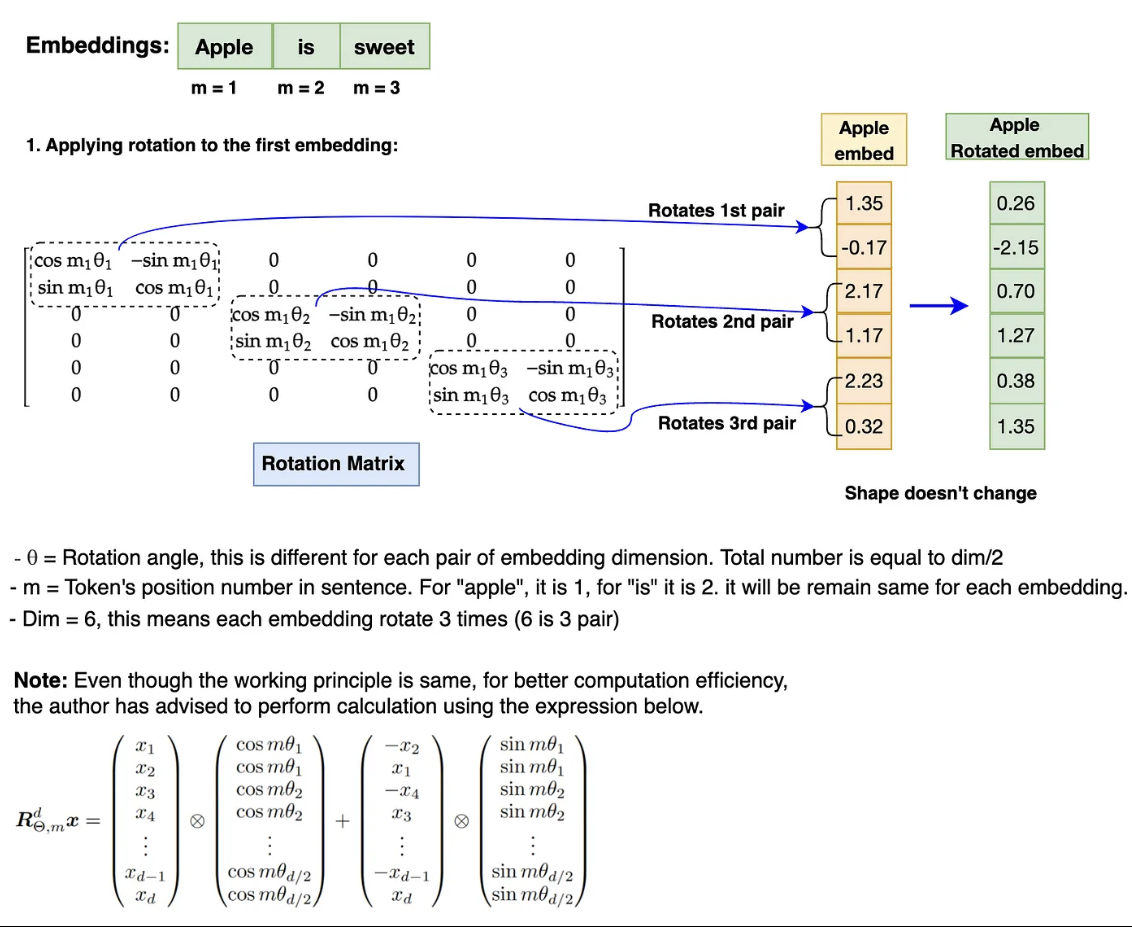
Vector embedding sau khi được chuẩn hóa sẽ được nhân vơi một ma trận xoay (rotation matrix). Nó sẽ làm biểu đổi giá trị của vector ban đầu thành các vector khác nhau phụ thuộc vào thứ tự của các từ được embedd. Có thể nhận thấy, lớp này chỉ chứa 2 tham số chính là theta (góc quay) và m tương ứng với thứ tự trong câu do đó, hiệu quả tính toán được cải thiện hơn rất nhiều so với lớp encoding cũ.
KV cache
Như đã đề cập ở trên, cơ chế hoạt động của Llama đó là sử dụng các token trước đó để dự đoán token tiếp theo sau nó. Dựa trên kiến trúc transformer, các ma trận attention được tính toán để tìm ra mối quan hệ giữa các token trong một đoạn input. Do đó, với mỗi quá trình dự đoán token kế tiếp, ma trận này lại được tính toán lại, tức phải xây dựng lại các ma trận này từ đầu (việc tính toán ma trận attention thường tốn rất nhiều bộ nhớ). Dựa vào đó, KV cache được giới thiệu để giải quyết vấn đề này trong quá trình inference.
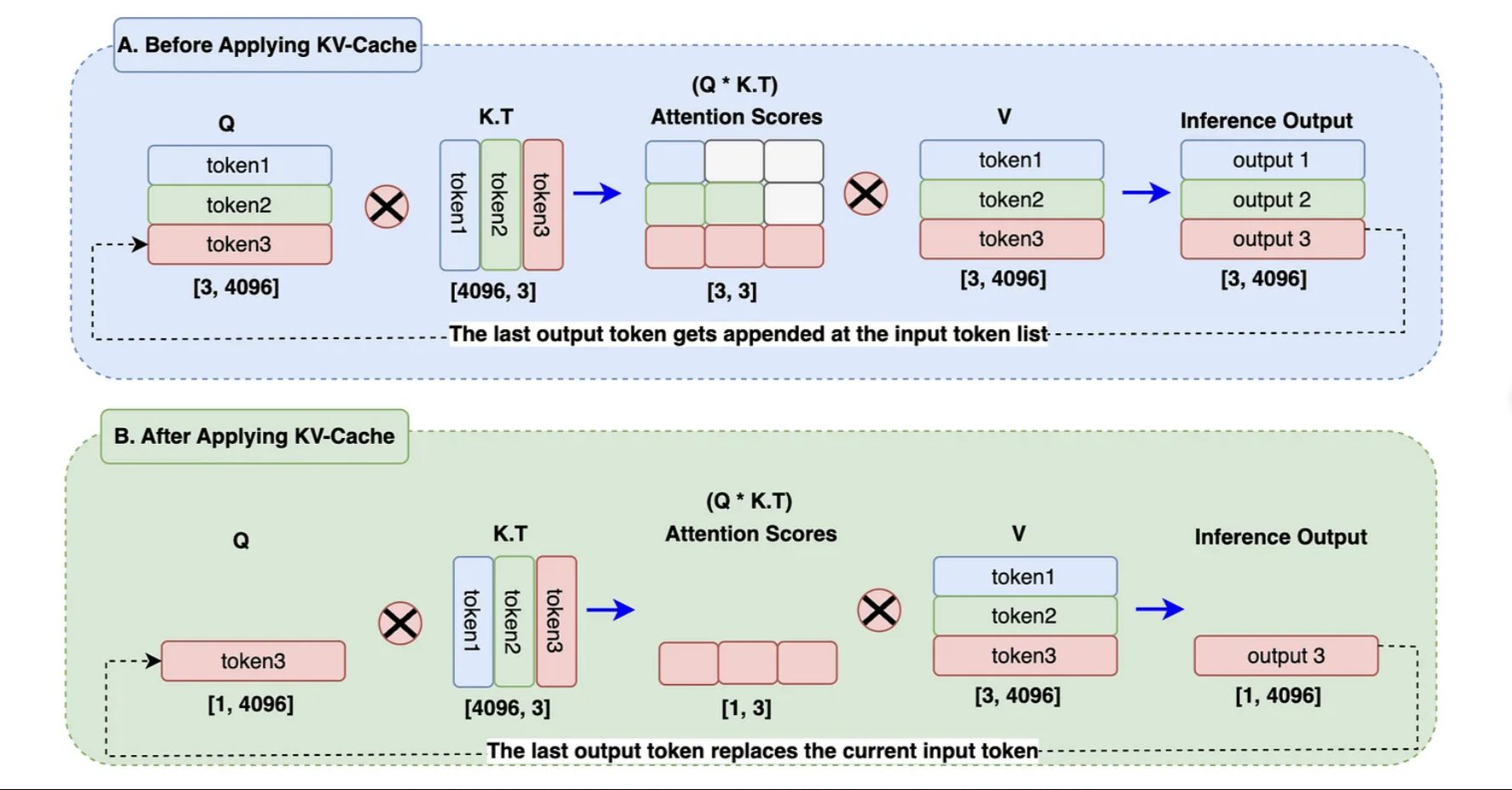
KV cache (Key - value cache) là phương pháp lưu lại các vector, token được sinh ra trước đó nhằm tối ưu việc tính toán ma trận self-attention. Lấy ví dụ với blog A, các token đầu vào lần lượt được tính toán theo thứ tự, tuy nhiên, tại token2, ma trận self-attention của nó dường như không đổi và nó được tính toán từ khi sinh ra token2. Do đó, ta hoàn toàn có thể lưu lại ma trận attention của các token trước đó và chỉ tìm kiếm mối quan hệ giữa token3 với các từ trước đó (được biểu diễn ở block B). Việc này giúp làm giảm thời gian tính toán lại các mối quan hệ giữa token1 và token2
Group Query Attention
Kiến trúc Llama1, lớp Multi-head attention được sử dụng kết hợp với một thư viện (xformers) giúp tính toán các ma trận này một cách nhanh chóng và hiệu quả hơn. Tuy nhiên, sang tới Llama 2 và 3, lớp này được thay thế bởi Group-query attention. 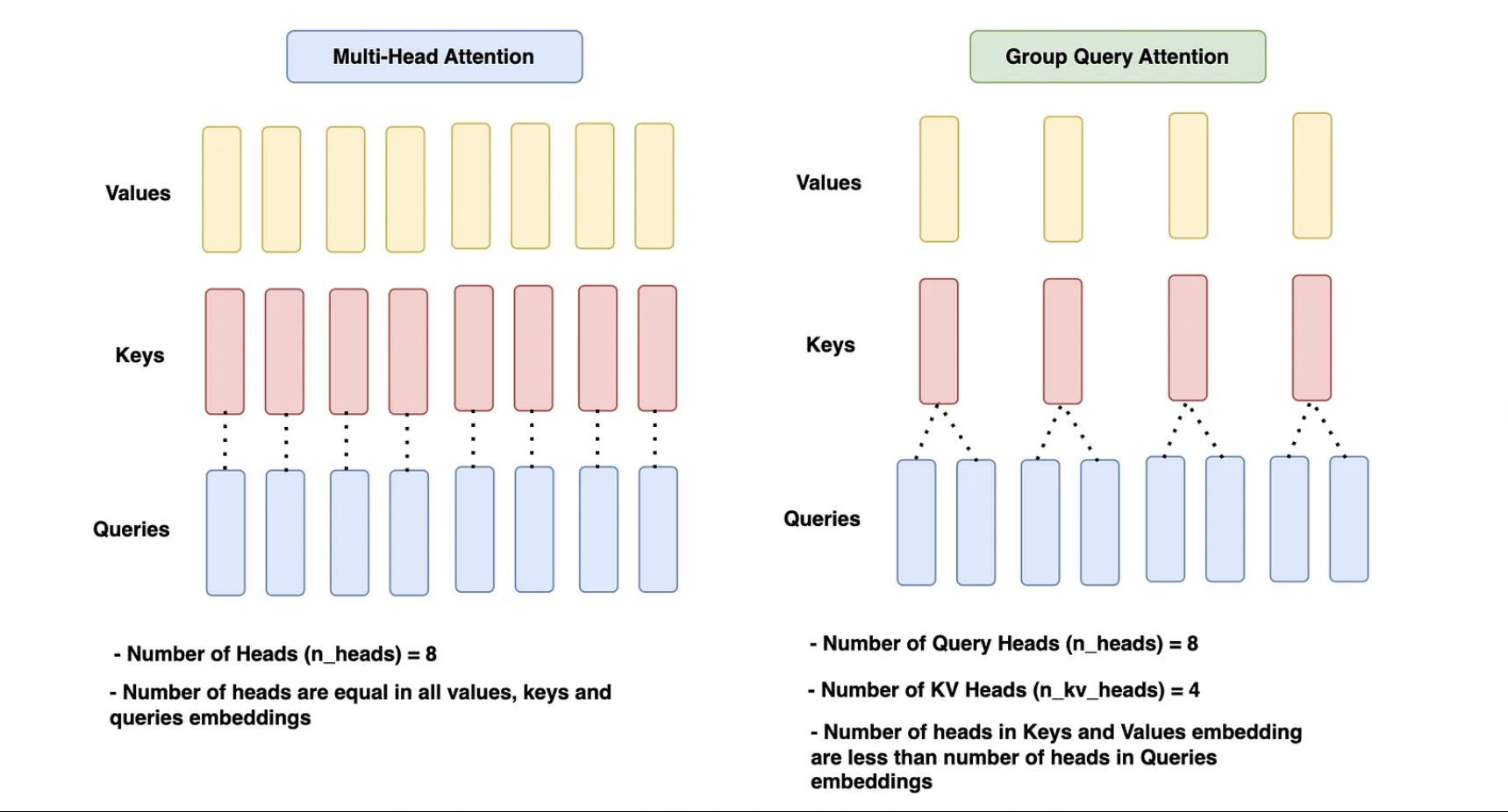
Nếu sử dụng Multi-head attention thông thường, với mỗi giá trị value và keys sẽ tương ứng với một query và sau đó chúng sẽ được stack lại với nhau (multi-head). Tuy nhiên, group query attention sẽ nhóm nhiều query lại thành một nhóm tương ứng với value và key. Việc này giúp tiết kiệm lượng lớn bộ nhớ, giảm thiểu số ma trận value - keys xuống rất nhiều. Việc sử dụng kiến trúc này giúp tối ưu cho KV cache khi nó phải lưu lại giá trị token trước đó do đó có thể làm dung lượng lưu trữ gia tăng. Theo tác giả, việc sử dụng lớp attention này không làm ảnh hưởng lớn tới độ chính xác của mô hình
FeedForward Network (SwiGLU Activation)
Được lấy cảm hứng từ PaLM, Llama sử dụng SwiGLU thay thế cho hàm ReLU trong lớp feedforward. Theo biểu đồ kiến trúc trên, sau khi đi qua lớp RMS Norm, các vector sẽ được truyền qua lớp feedforward, lớp này có tác dụng mở rộng kích thước của vector thông qua các hidden units giúp mô hình có thể học được các tính chất phức tạp hơn từ token đầu vào. Vậy tại sao tác giả lại thay thế ReLU thành SwiGLU?
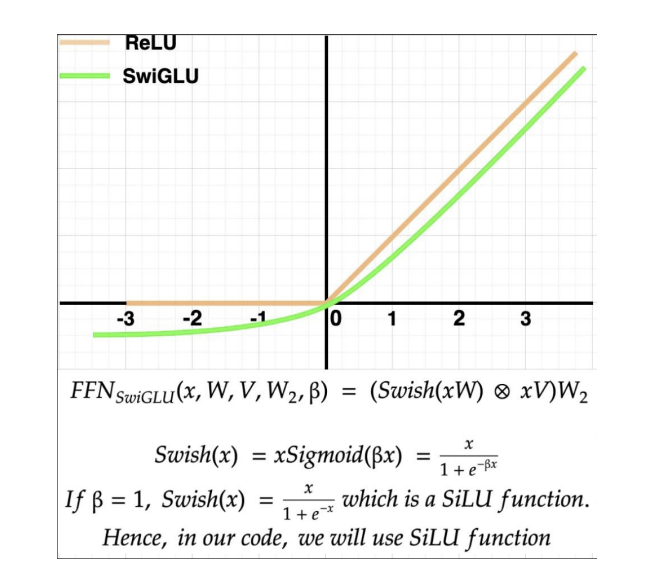
Dựa vào hình trên, có thể nhận thấy, hàm SwiGLU gần như tương tự so với ReLU với dữ liệu x dương. Tuy nhiên, với chiều âm, hàm này có output là các giá trị âm, thay vì bằng 0 như ReLU, điều này giúp cải thiện, làm quá trình học trở nên ổn đinh hơn so với ReLU. Dựa vào nhóm tác giả, hàm này có tính ổn định cao hơn và cả hiệu quả tốt hơn so với sử dụng ReLU.
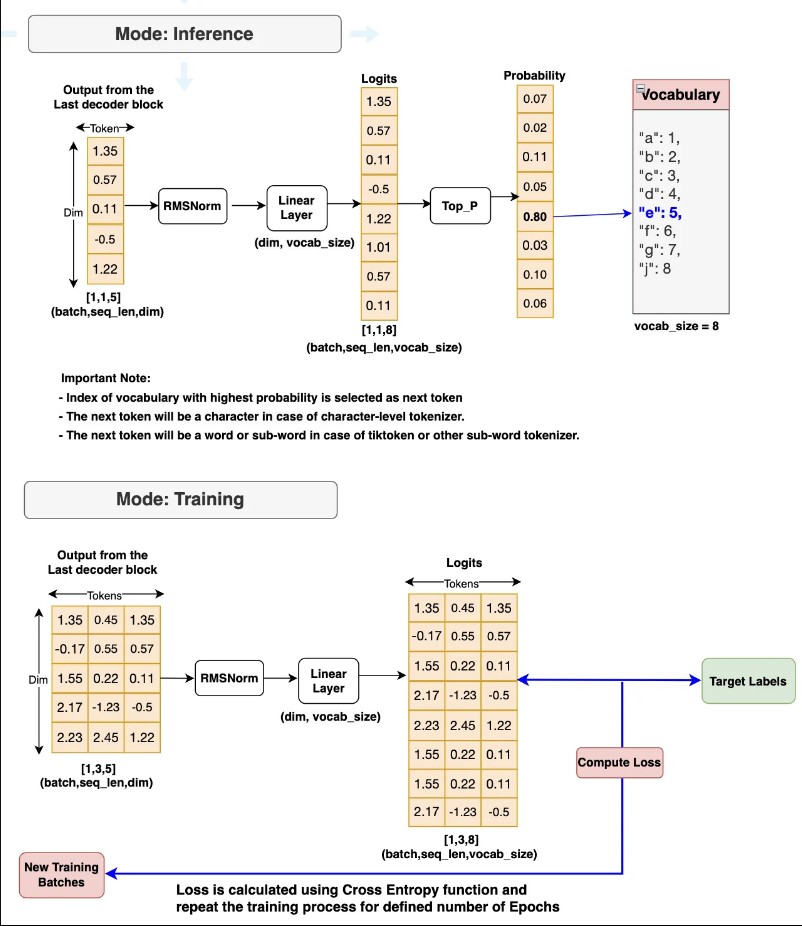
Khối output
Tương tự như các khối output của các mô hình khác, tùy thuộc vào quá trình training và inference, lớp này sẽ thực hiện các quá trình khác nhau. Với quá trình infer, lớp sẽ đưa ra dự đoán về token kế tiếp dựa vào output của khối decoder trước đó. Ngược lại, với quá trình training, nó sẽ tính loss với target value và thực hiện backward.
Kết luận
Trong bài blog hôm nay, chúng ta đã tìm hiểu về kiến trúc của mô hình Llama - một trong những mô hình phổ biến và nổi tiếng. Hy vọng mọi người cảm thấy hay và hãy để lại lời góp ý thông qua email để mình cải thiện hơn nhé
Tham khảo
- https://arxiv.org/abs/2302.13971
- https://medium.com/towards-artificial-intelligence/build-your-own-llama-3-architecture-from-scratch-using-pytorch-2ce1ecaa901c
- https://arxiv.org/abs/2307.09288