LoRA, QLoRA - Huấn luyện LLM chưa bao giờ nhanh và nhẹ đến thế !

Giới thiệu
Xin chào mọi người, khá lâu rồi mình mới quay lại trong việc viết blog cá nhân, trong tuần vừa qua mình được giao nhiệm vụ nghiên cứu về cách fine tuning các mô hình ngôn ngữ lớn và mình bắt đầu hành trình mới trong khám phá vùng đất “hot trend” này. Trong bài viết hôm nay, mình sẽ giới thiệu cho mọi người về LoRA và một cải tiến của nó QLoRA - kĩ thuật fine tuning LLMs một cách hiệu quả.
Như mọi người đã biết, fine-tuning là phương pháp thay đổi bộ tham số của mô hình ban đầu dựa trên một tập dữ liệu nhằm thực hiện một tác vụ hay tập tác vụ cụ thể nào đó. Nhiều bạn sẽ hỏi tại sao phải fine tuning trong khi các LLMs hiện đại với hàng tỷ tham số (GPT, Gemma) đã thực hiện tốt trong nhiều công việc phức tạp khác nhau chỉ cần thông qua các phương pháp prompt ? Nhưng trên thực tế, do được huấn luyện trên đa dạng về bộ dữ liệu, các kiến thức chuyên biệt của nó về một tác vụ cụ thể sẽ không được tối ưu hoàn toàn do đó, để phục vụ mục đích của chúng ta, fine-tuning vẫn tiếp tục được sử dụng và phát triển
Làm sao để fine-tuning một LLM?
Bản chất fine-tuning là một phương pháp trong transfer learning, ở đó các pretrained sẽ được sử dụng để huấn luyện trên bộ dữ liệu nhỏ của người dùng. Một ý tưởng ban đầu cho việc này đó là train lại toàn bộ mô hình hoặc chỉ train một số layer của mô hình. Tuy nhiên, trên thực thế, việc huấn luyện này gặp rất nhiều khó khăn đặc biệt với các mô hình có nhiều tham số, việc train lại và lưu lại toàn bộ tham số của chúng cần có yêu cầu về cơ sở hạ tầng tương đối lớn. Để cải thiện điều đó, nhiều phương pháp đã được đưa ra để giảm thiểu số lượng tham số phải huấn luyện và bộ nhớ lưu trữ mô hình.
Adpater-tuning
Trước tiên, phương pháp sử dụng adapter được gọi là “adapter-tuning”, tạo ra để giải quyết vấn đề về lượng tham số của LLMs. Thay vì huấn luyện tạo bộ tham số của pre-trained, tất cả các tham số này dều được giữa nguyên (frozen), với mỗi layer sẽ được thêm vào một số layer khác gọi là adapter, các layer này sẽ được sử dụng để huấn luyện trên custom dataset.
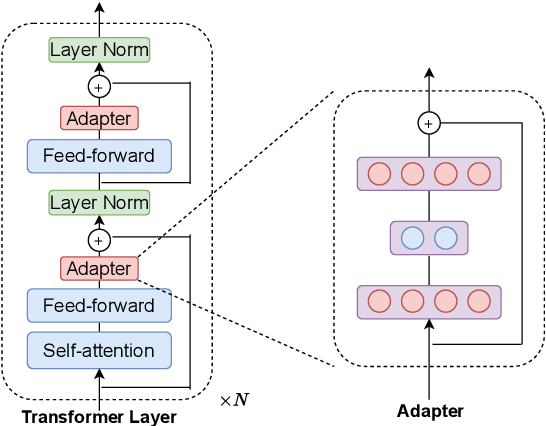
Có thể thấy, lượng tham số được giảm đi đáng kể, tuy nhiên việc thêm các adapter này lại làm cho mô hình tăng về kích thước dẫn tới quá trình infer sẽ tốn nhiều thời gian hơn so với trước.
Ý tưởng ban đầu về LoRA
Vẫn giải quyết vấn đề về lượng tham số, LoRA được giới thiệu như một phương pháp hiệu quả hơn trong việc vừa giảm thiểu số lượng tham số cần huấn luyện mà vẫn đảm bảo được hiệu suất của mô hình. Quay lại với bản chất của fine-tuning, nếu gọi $w$ là tham số của mô hình pretrained, khi đó, tham số sau quá trình fine-tuning được định nghĩa như sau:
\[W = w + \Delta w\]Dựa vào công thức trên, ý tưởng của LoRA đó là giữa nguyên các tham số của pretrained (w) và chỉ cập nhật các tham số $\Delta w$. Vậy thì rốt cuộc số lượng tham số của mô hình đâu có thay đổi ? Kích thước của $w$ và $\Delta w$ là bằng nhau cơ mà?
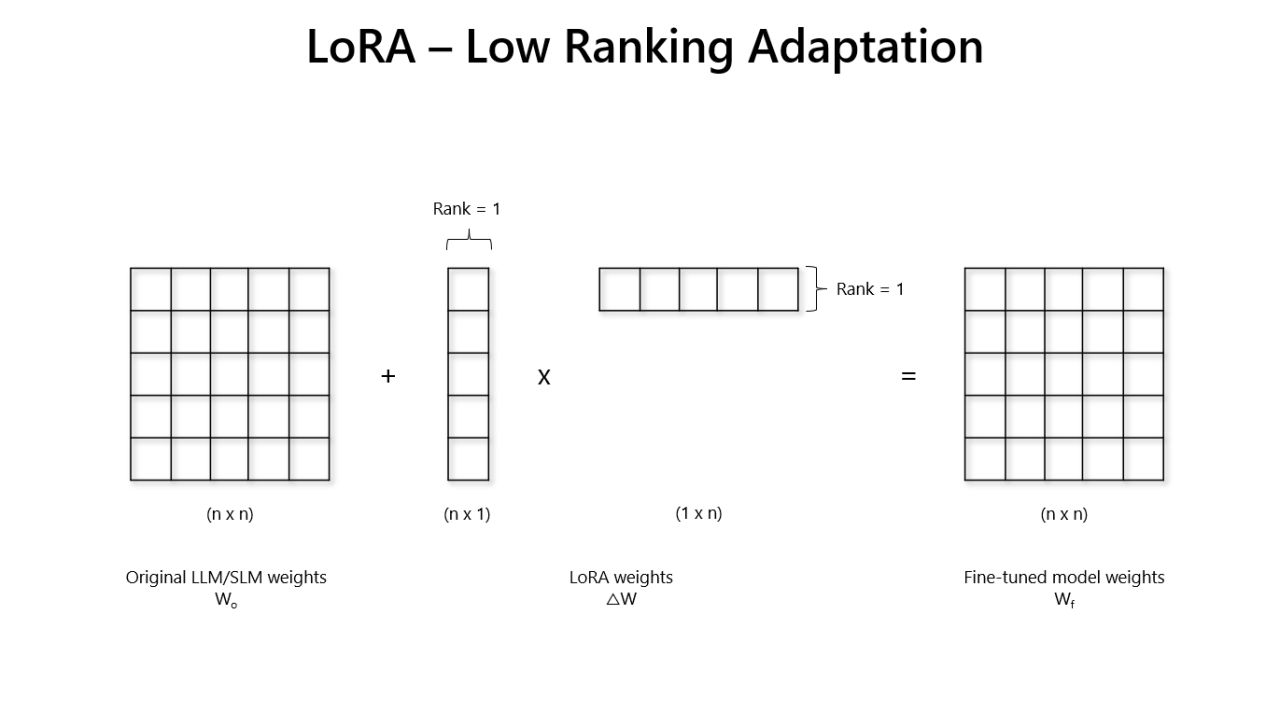
Để giải thích điều trên, hãy nhìn vào tên gọi của LoRA (Low-Rank Adaptation of Large Language Models), trong đó “Low-Rank” để chỉ một ma trận có rank thấp - tức dù kích thước của nó rất lớn, nhưng các hàng lại không độc lập tuyến tính, và thông tin thực sự của ma trận này chỉ nằm trên phần độc lập tuyến tính. Dựa vào nhận định đó, các phương pháp phân rã ma trận (decomposition) được sử dụng lên $\Delta w$ để giảm thiểu số lượng tham số phải huấn luyện. Mình giải thích rõ hơn trong phần kiến trúc của LoRA.
Kiến trúc của LoRA
Như mình đã nói ở trên, mục tiêu của LoRA là làm sao để có thể biểu diễn ma trận $\Delta w$ nhẹ hơn, theo đó, LoRA đã sử dụng các phép decomposition để biểu diễn ma trận trên thành tích của các ma trận con nhẹ hơn, độ nặng tính toán thấp hơn so với sử dụng ma trận gốc, một số phép matrix decomposition có thể kể đến là SVD, LU, … Các phép biến đổi này giúp phân tách một ma trận lớn hơn thành nhiều ma trận nhỏ và chúng có thể tái tạo, chuyển đổi ngược lại cho nhau. Nhóm nghiên cứu đã biểu diễn ma trận $\Delta w$ bằng tích của 2 ma trận low-rank đó là A và B ($\Delta w = BA$) với số chiều thấp hơn nhiều so với ma trận gốc
Khi đó, xét trên một layer của mô hình (với output là $y$, input là $x$), ouput của layer đó sẽ được biểu diễn như sau:
\[y = (w + \Delta w)x = wx + BAx\]Quá trình fine-tuning thực chất là học ra ma trận A và B biểu diễn $\Delta w$. Đến bước này, chắc hẳn mọi người sẽ thấy ngay việc lượng tham số đã được giảm đi như thế nào. Nếu xét $\Delta W$ có mxn chiều, thì khi đó thông qua biểu diễn low-rank của A và B, các chiều chỉ được gọi gọn lại nx1 chiều cho mỗi ma trận. Hay nói cách khác, số lượng tham số cần phải học là 2 x n thay vì nxn như trước - tức khối lượng đã giảm đi n/2 lần. Dựa vào hình minh họa dưới, việc học B và A cũng tương tự như việc huấn luyện các mạng neural thông thường, tuy nhiên hiện tại LoRA chỉ hỗ trợ phân ra các Linear layer.
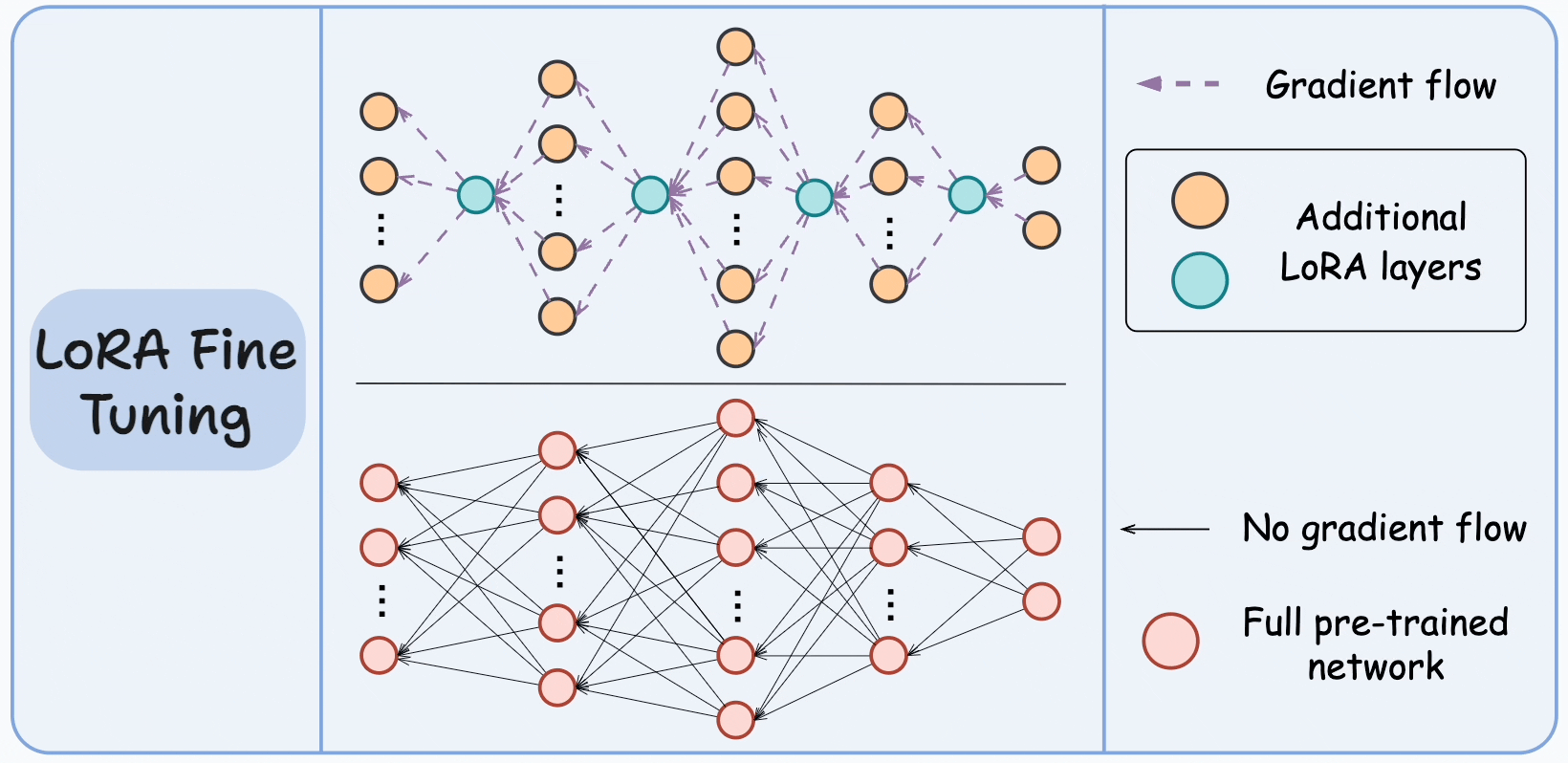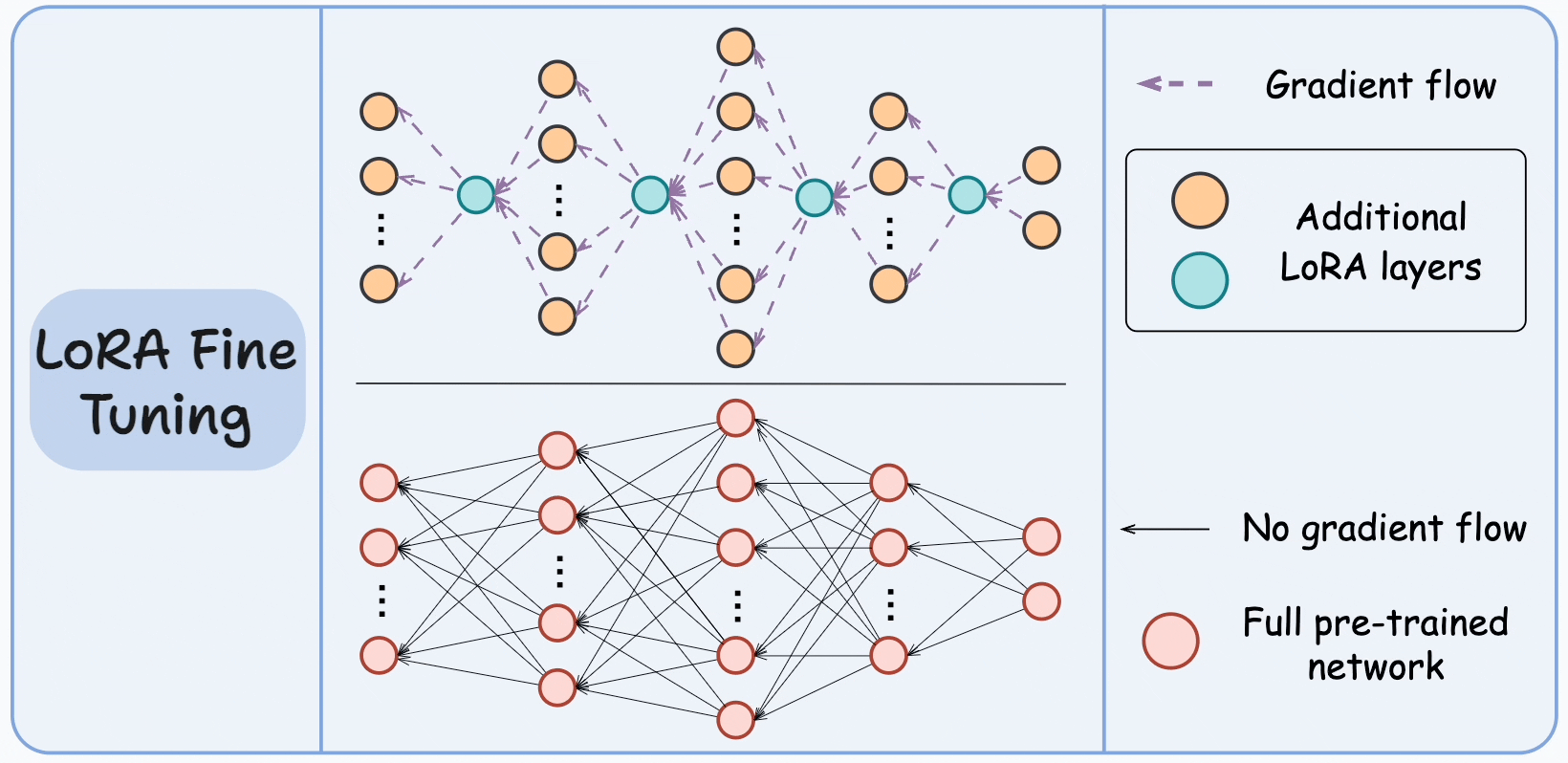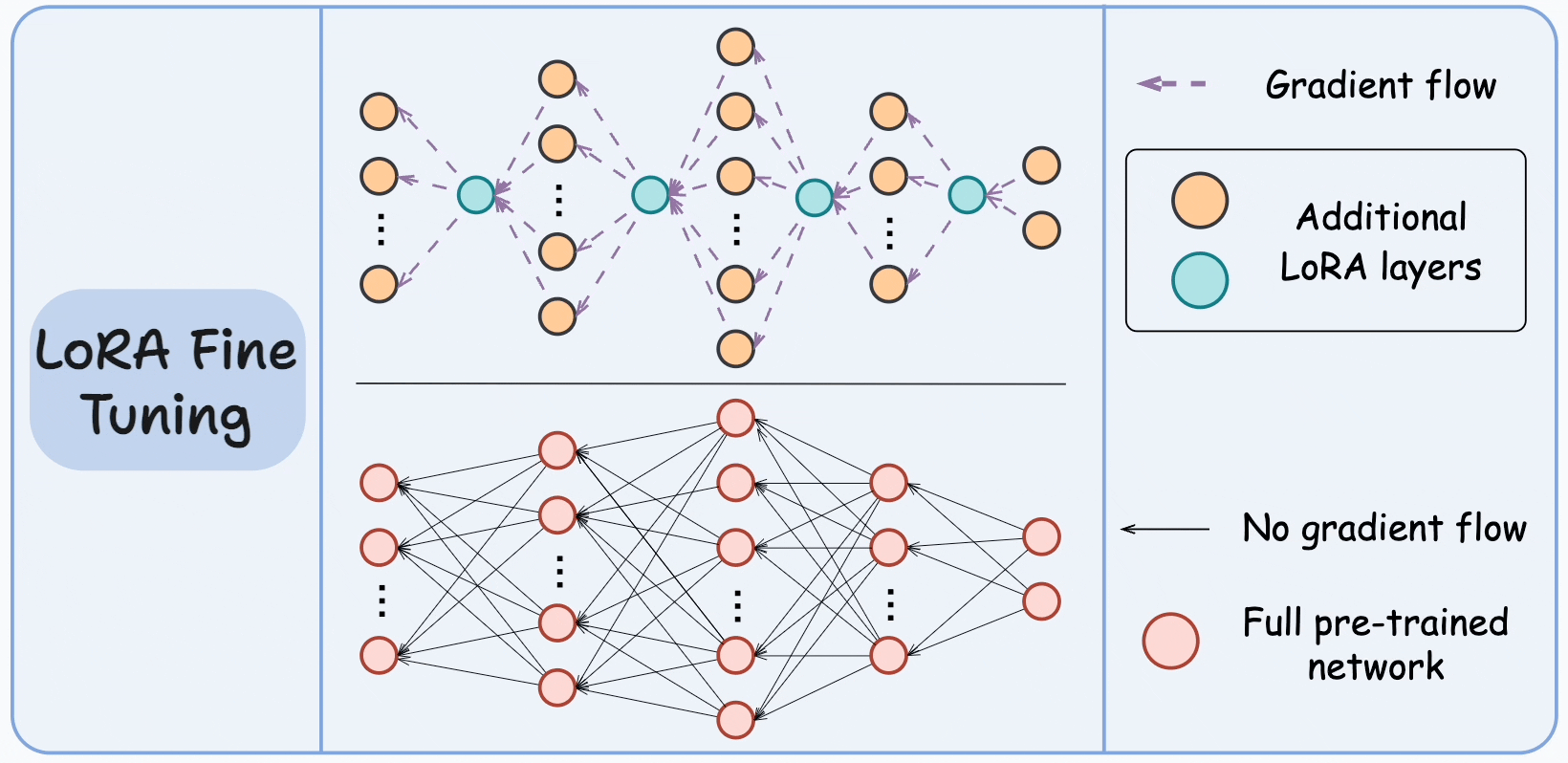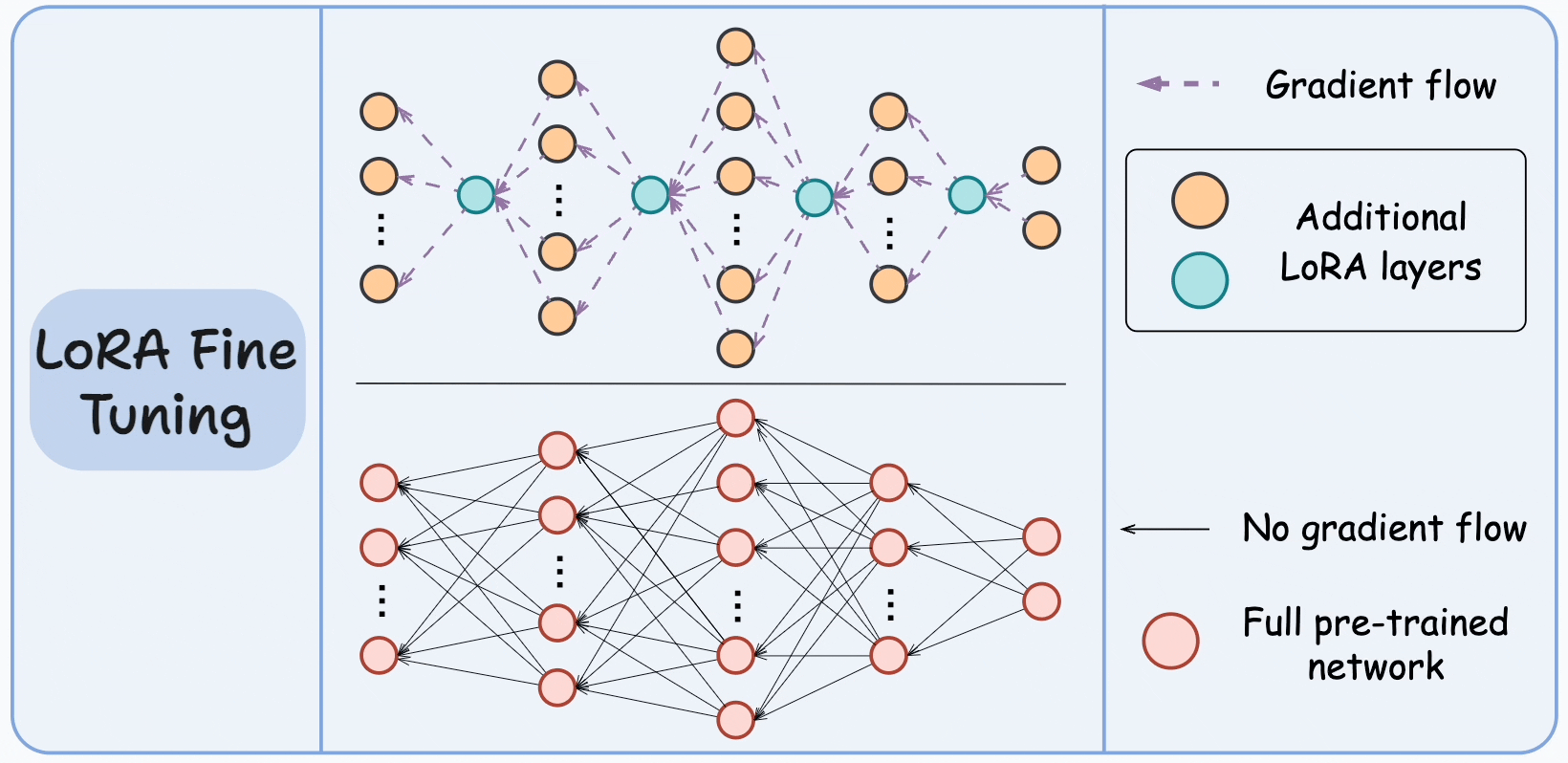
Thông qua đó, LoRA đã giúp số lượng tham số được giảm đi đáng kể, các tác giả đã chứng minh trên mô hình GPT3 175B, phương pháp này giảm số lượng tham số huấn luyện đi 10.000 lần so với việc huấn luyện thông thường và giảm đi 3 lần yêu cầu về GPU.
Làm sao để fine-tuning LLM trên máy tính cá nhân?
Như mình đã đề cập ở trên, dù lượng tham số trong training đã giảm nhưng việc fine-tuning vẫn cần rất nhiều GPU và để sử dụng các mô hình hàng tỷ tham số ngay trong quá trình infer cũng đã không đơn giản. Đặc biệt với sự phát triển của IOT, việc tích hợp các mô hình AI vào trong các thiết bị này sẽ là một bước tiến lớn, nhưng các thiết bị này lại không đủ tài nguyên về phần cứng để infer một cách nhanh chóng. Để giảm thiểu yêu cầu về phần cứng và vẫn không làm mất đi hiệu suất của mô hình, các phương pháp lượng tử hóa (quantization) được ra đời để giải quyết vấn đề trên
Quantization - cách làm giảm kích thước của mô hình
Kích thước của một mô hình được xác định bởi số lượng tham số của nó, thực tế, chính độ chính xác của mô hình quyết định lớn đến kích thước của mô hình. Nếu tham số của mô hình được biểu diễn theo dạng float-32 tức 32 bit, làm kích thước mô hình rất lớn. Do đó, các phương pháp quantization sẽ chuyển đổi phương thức biểu diễn các tham số này (ví dụ từ float32 - int8) giúp giảm kích thước lưu trữ, tuy nhiên độ chính xác của mô hình sẽ giảm đi đôi chút.
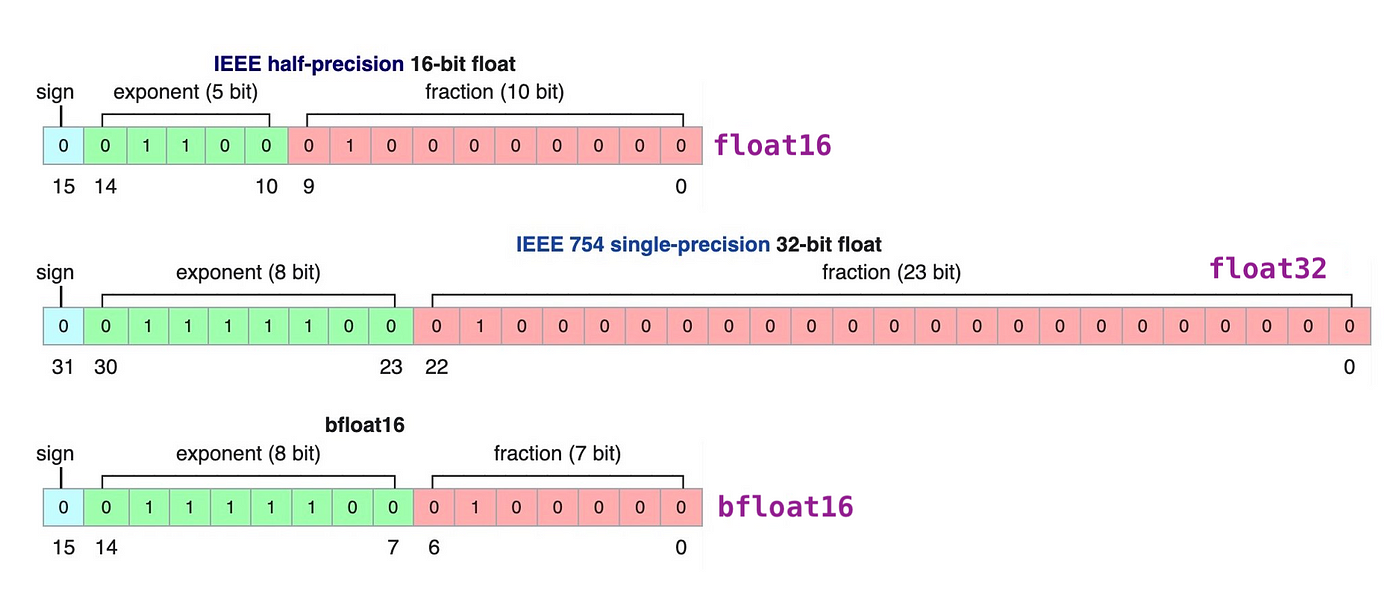
Một nghiên cứu 2022 đã giới thiệu phương pháp lượng tử hóa 8bit (LLM.int8()) giảm kích thước mô hình từ biểu diễn 32-bit xuống còn 8-bit (1/4 lần). Tuy nhiên việc này làm giảm tương đối độ chính xác của mô hình, họ đã phát hiện ra, trong phép nhân ma trận, các outlier thường xuất hiện và chúng quan trọng hơn so với non-outlier. Để xử lý việc đó, người ta sẽ lưu các giá trị này dưới dạng Float16 và còn lại sẽ là int8 (quá trình này được phát triển trong bitandbytes)
Ý tưởng về QLoRA
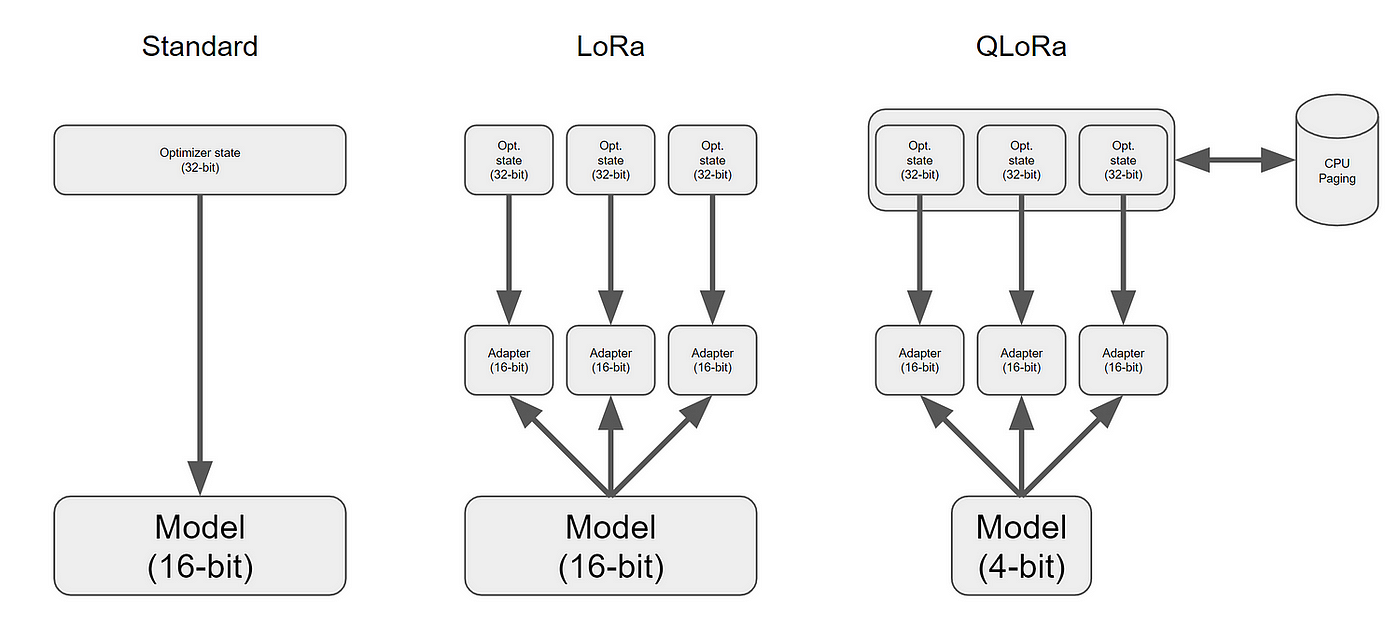
Dựa vào các phương pháp quantization trên, QLoRA được phát triển với bản chất là sự kết hợp giữa Quantization + LoRA. Với sự phát hiện này, việc fine-tune các mô hình hàng tỷ tham số trở nên dễ tiếp cận hơn khi chỉ yêu cầu nhỏ về GPU và dung lượng cũng được giảm đi đáng kể (7B tham số ~ 5 - 6 G) hoàn toàn có thể fine-tune trên Colab
Một ý tưởng mới trong QLoRA đó là biểu diễn số dưới dạng NF4 - chỉ có 4 bit biểu diễn nhưng có độ chính xác tương đối cao. QLoRA sử dụng phương pháp Quantile Quantization, coi khoảng giá trị như một phân phối, và phân chia chúng theo khoảng sao cho từng khoảng có xác suất xảy ra bằng nhau. Với các số outlier, thay vì nó quantize toàn bộ tensor thì nó chia nhỏ tensor thành từng chunks và quantize từng chunks một cách riêng biệt. Bên cạnh đó, một vấn đề của biểu diễn này đó là xác định quantile cho mỗi chunks, nhóm tác giả đã tìm ra được rằng, đa số các tensor được tuân theo một phân bố chuẩn với mean là 0. QLoRA quantize về mạng neuron về cụ thể một khoảng đó là [-1, 1].
Tuy nhiên, QLoRA được quantize về tham số NF4 chưa thể thực hiện tính toán, do đó, người ta phải dequantize lên BF16 để tính toán và hiện tại chỉ hỗ trợ cho Linear Layer
Quá trình của QLoRA
Quá trình tính toán của QLoRA tương tự với LoRA, tuy nhiên, các weight sẽ được quantize xuống dạng NF4 trong lưu trữ và dequantize thành BF16 trong tính toán. Đồng thời các ma trận B và A được biểu diễn dưới dạng BF16 để phục vụ hỗ trợ tính toán. Do đó, quá trình tính toán trên một layer của QLoRA như sau:
\[Y^{BF16} = X^{BF16} dequant(dequant(c_1^{FP32}, c_2^{k-bit}), W^{NF4}) + B^{BF16}A^{BF16}X^{BF16}\]Quá trình dequantize được diễn ra 2 lần do nó được quantize 2 lần, quá trình này là do khi thực hiện quantize theo chunk, các chunk sẽ có hằng số quantize riêng cho nó làm tăng bộ nhớ để lưu trữ hằng số quantize
Kết luận
Hôm nay, mình đã giới thiệu sơ qua về 2 phương pháp fine-tuning mô hình một cách hiệu quả. Tóm tắt lại, bản chất LoRA là huấn luyện trên một tham số mà ở đó nó được tách thành các ma trận có rank thấp hơn để giảm thiểu tính toán. Thêm vào đó, QLoRA sử dụng thêm kĩ thuật quantization để tiết kiệm tính toán trong quá trình fine-tune bằng LoRA. Để hình dung rõ nhất về blog này, bạn có thể tham khảo mình vẽ dưới đây :
Tham khảo
https://arxiv.org/abs/2305.14314
https://arxiv.org/abs/2208.07339
https://blog.tnminh.com/blog/from-lora-to-longlora/from-lora-to-longlora-p2
https://arxiv.org/abs/2106.09685
https://medium.com/gitconnectedin-depth-understanding-of-lora-and-finetuning-a-llm-using-lora-266aaa991fcd