Papers Explained 01 : Dolma

Giới thiệu
Đây là bài đầu tiên trong một series mới của mình với tên gọi là Papers Explained, cũng như tên gọi của nó, đây là nơi mình ghi lại nội dung, góc nhìn và diễn giải lại câc paper một cách đơn giản và dể hiểu nhất. Trong bài đầu tiên này, mình sẽ giới thiệu về một paper có tiêu để là “Dolma - an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research” được ra mắt vào tháng 1 năm 2024 và submit tại ACL 2024.
Các mô hình ngôn ngữ lớn hiện nay thể hiện khả năng vượt trội trên nhiều tác vụ từ đơn giản tới phức tạp. Tuy nhiên, phần lớn chúng ta - những người lập trình viên AI thông thường chỉ huấn luyện trên các pretrained có sẵn được công bố, huấn luyện trước bởi các công ty lớn mà không đủ tài nguyên huấn luyện lại từ đầu các mô hình này. Với một số open-source như Llama,.. các bài báo đều nói rõ quá trình thu thập và xử lý dữ liệu pretrained, tuy nhiên với những close-source như GPT-3,.. thi điều này không được công bó, đồng thời các nghiên cứu về ảnh hưởng của bộ pretrained (như phân bố các domain, kích thước, ..) lên các mô hình cũng không nhiều. Dựa trên gap đó, các nhà nghiên cứu đã giới thiệu bài báo “Dolma - an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research” xây dựng một bộ dữ liệu pretrain gồm 3T token, giới thiệu cách thức họ thu thập và xử lý dữ liệu, đồng thời thử nghiệm các yêu tố về dữ liệu tác động lên kết quả của mô hình pretrained và cung cấp bộ Dolma tookit giúp xử lý, quản lý dữ liệu.
Tổng quan về bộ dữ liệu
Các bộ dữ liệu pretraining đã được thu thập và phát triển từ rất lâu, đồng thời một số các open-source model cũng sử dụng chúng trong quá trình huấn luyện pretrained. Tuy nhiên, các bộ dữ liệu này thường có một số giới hạn về kích thước như C4 (175B token), Pile (387B token) hoặc thiếu sự đa dạng (Falcon, RedPajama),.. . Dựa trên những nhược điểm đó, bộ dữ liệu Dolma được xây dựng với kích thước lớn và độ đa dạng về nguồn dữ liệu.
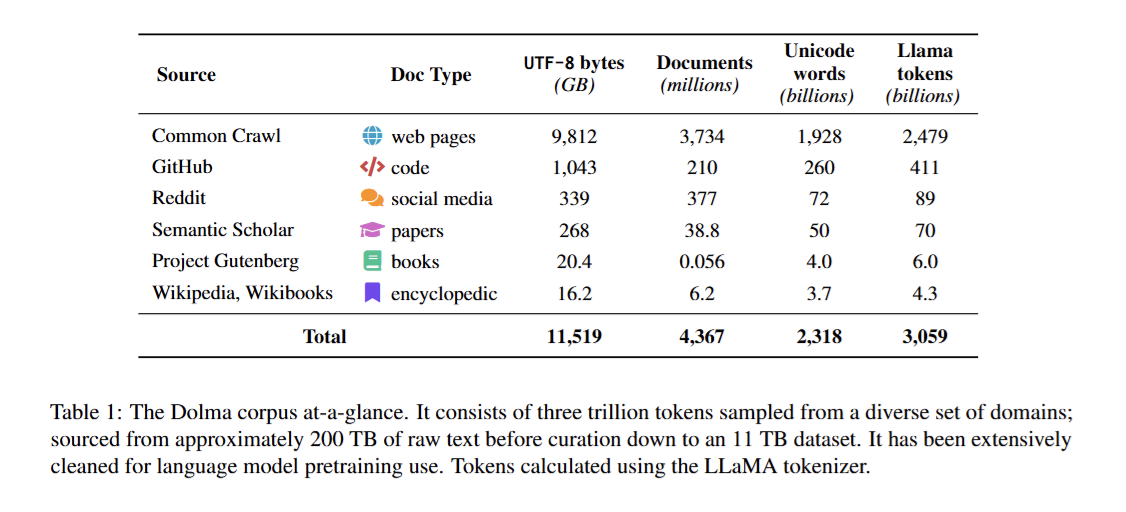 Hình 1: Phân bố dữ liệu của bộ Dolma
Hình 1: Phân bố dữ liệu của bộ Dolma
Theo đó, bộ Dolma bao gồm hơn 3T token (4B document), chỉ chứa tiếng Anh và được thu thập từ 6 nguồn chính (Common Crawl, Github, Reddit,..) thường được thấy tại dữ liệu huấn luyện của các pretrained. So sánh với các bộ dữ liệu đã được public trước đó, Dolma có kích thước lớn hơn rất nhiều, chất lượng của dữ liệu gần như tương đương trong khi vẫn giữ được tính đa dạng của dữ liệu.
Bộ dữ liệu được nhóm tác giả thiết kế trên 4 mục tiêu chính :
Be consistent with prior language model pretraining recipes (Có sự thống nhất đối với các bộ dữ liệu trước đó) : vì sử dụng cùng nguồn dữ liệu và các phương pháp tạo ra các bộ dữ liệu trước đó, bộ dữ liệu này có thể được sử dụng để nghiên cứu đối với các mô hình khác kể cả close-source
When in doubt, make evidence-backed decisions (Đưa ra lựa chọn dựa trên thực nghiệm) : trong các quy trình xử lý dữ liệu, với những phương pháp không được làm rõ bởi các pretrained, nhóm tác giả thực nghiệm nhiều phương pháp và lựa chọn phương pháp có hiệu qủa tốt nhất trên mô hình.
Large scale data to train large models. (Dữ liệu lớn - huấn luyện mô hình lớn) : phát triển một corpus kích thước lớn (2-3T token) để nghiên cứu mối quan hệ giữa model size và data size.
Make necessary adjustments to preserve openness. (Thay đổi để giữ tính mở) : lựa chọn, xử lý dữ liệu không nhạy cảm, không có thông tin cá nhân hoặc đang trong tranh cãi
Sau khi công bố bộ dữ liệu, nhóm tác giả cũng chỉ ra một số hạn chế của bộ dữ liệu như sau :
- Bộ dữ liệu chỉ bao gồm ngôn ngữ tiếng Anh
- Kết quả thử nghiệm bị giới hạn, chỉ sử dụng mô hình 1B và có một kiến trúc autoregressive
- Chỉ đánh giá hiệu quả trên các task phổ biến và cũng không thể đánh giá đầy đủ trên các task quan trọng (viết code)
- Do kích thước lớn, không thể kiểm tra, đánh giá thủ công bộ dữ liệu
Quá trình xử lý dữ liệu
Dolma Tookit
Như đã đề cập ở trên, bài báo tập trung vào quy trình xử lý bộ dữ liệu pretraining, đưa ra các thực nghiệm để lựa chọn phương pháp tốt nhất cho mỗi phase. Quy trình xử lý, biến đổi dữ liệu này vô cùng phức tạp khi dữ liệu tương đối lớn và chưa được kiểm soát chất lượng (dữ liệu thô). Dựa trên đó, nhóm tác giả đã giới thiệu một bộ tookits giúp xử lý dữ liệu một cách nhanh chóng, bằng cách chia quá trình này thành 2 bước :
Filtering : bao gồm các bước như lọc bỏ văn bản không phù hợp (không phải tiếng anh, chứa nội dung độc hại), lọc bỏ thông tin không phù hợp (thông tin độc hại, thông tin cá nhân,..). Toolkit cài đặt các thuật toán filtering : scoring method (linear classifier, language model perplexity),.. xác định và loại bỏ song song trên lượng lớn dữ liệu
Mixing : thực hiện các bước up/down scaling (thay đổi tần suất dữ liệu), deduplication (loại bỏ trùng lặp),.. Đây là các tác vụ thường thực hiện trên nhiều tệp dữ liệu với mục tiêu kết hợp chúng lại thành các tệp nhỏ hơn. Toolkit sử dụng Bloom filter - một thuật toán kiểm tra một phần tử có thuộc một tập cho trước với thời gian tuyến tính và đạt được hiệu quả trong việc lọc dữ liệu bị trùng lặp và loại bỏ dữ liệu trong tập test trong quá trình thử nghiệm.
Lựa chọn cách thức xử lý dữ liệu
Dựa trên bộ công cụ vừa xây dựng và dữ liệu thô từ các nguồn trên, nhóm tác giả đã sử một pipeline chung cho từng nguồn dữ liệu khác nhau - nhưng thực hiện các phương pháp khác nhau trên từng thành phần của pipeline chung này. Pipeline chung này cũng chính là pipeline thường được dùng trong quá trình xây dựng bộ dữ liệu pretrained cho LLM.
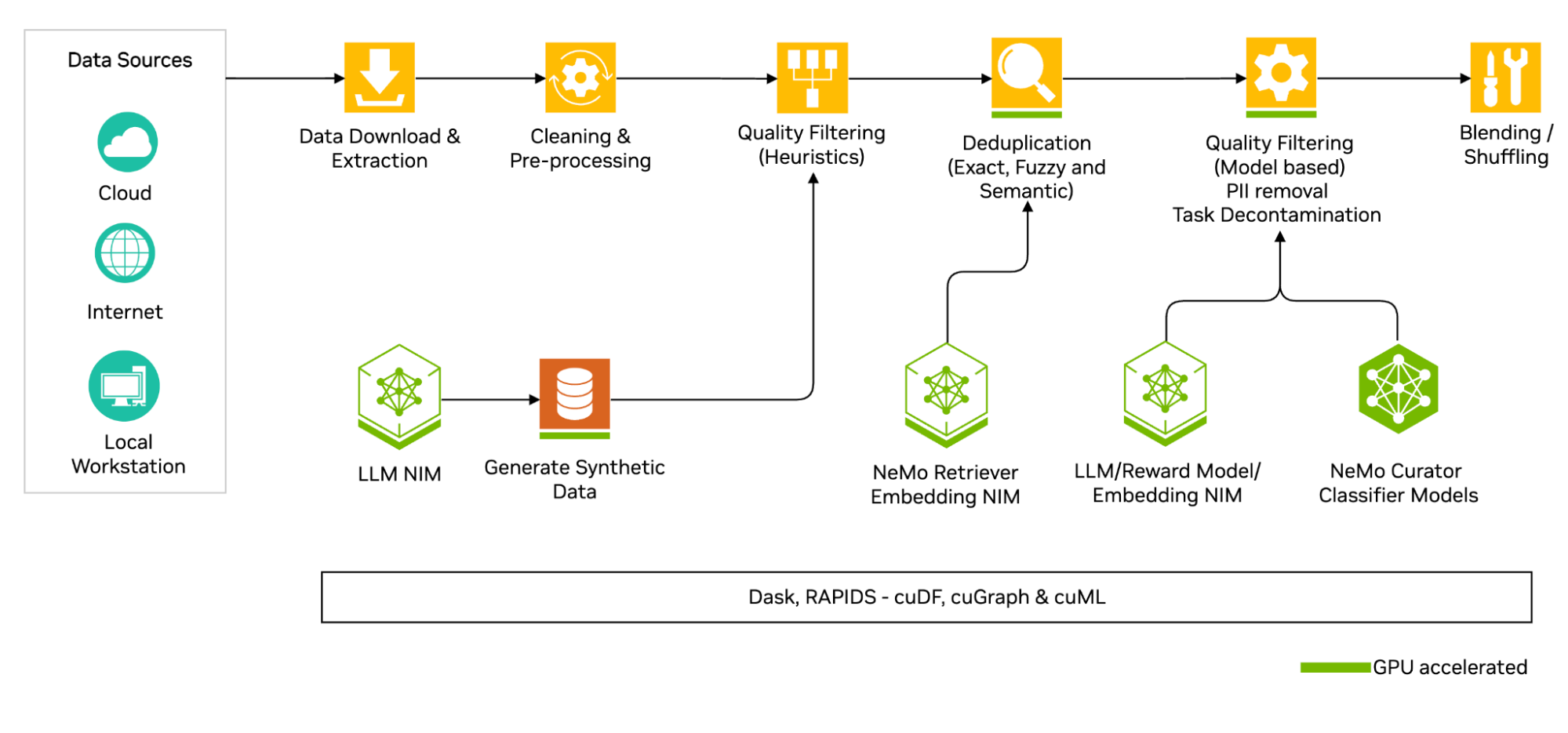 Hình 3: Tổng quan pipeline xử lý dữ liệu pretraining
Hình 3: Tổng quan pipeline xử lý dữ liệu pretraining
Với mỗi thành phần của quy trình trên, dữ liệu khác nhau có cách thức xử lý khác nhau, nhóm tác giả ưu tiên lựa chọn các phương pháp của các mô hình trước đó, tuy nhiên với các trường hợp chưa từng gặp, nhóm tác giả đánh giá hiệu quả của mô hình trên từng phương pháp xử lý. Chi tiết hơn, nhóm tác giả huấn luyện một mô hình 1.2B tham số với kiến trúc decoder-only (OLMo), đồng thời lựa chọn các benchmark khác nhau với 2 tiêu chí : đã được sử dụng bởi các mô hình trước đó và có thể capture nhiều khả năng của LLM. Các thử nghiệm đều sử dụng phương pháp in-context prompting, zero-shot trên mô hình được huấn luyện.
Cleaning & Pre-processing
Trong phase này, nhóm tác giả thực hiện loại bỏ các dữ liệu không cần thiết và các văn bản không phải tiếng anh.
Dữ liệu web : sử dụng CCNet tương tự như Llama hay RedPajama để lọc ngôn ngữ cũng như loại bỏ các document bị lặp. CCNet sử dụng FastText để xác định ngôn ngữ chính trong mỗi document, sau quá trình lọc này, dữ liệu web còn lại 27.7TB so với tổng 175TB của bộ Common Crawl trước đó.
Dữ liệu code : được thu thập từ github và loại bỏ các file có extension không phải file code (csv, json, ..)
Dữ liệu từ social media : chủ yếu được thu thập từ reddit bao gồm các đoạn comment nằm trong bài viết (submission). Tại đây, tác giả đưa ra 3 cách để biểu diễn dữ liệu dạng này bao gồm : Atomic content - mỗi comment và submission là một doc độc lập, partial threads - tất cả comment trong cùng một thread (đoạn hội thoại ) và submission là doc dộc lập ; full threads - kết hợp toàn bộ submission và comment của nó là 1 doc. Thông qua thử nghiệm huấn luyện trên các dạng biểu diễn trên, cách biểu diễn dạng atomic đạt hiệu quả tốt nhất
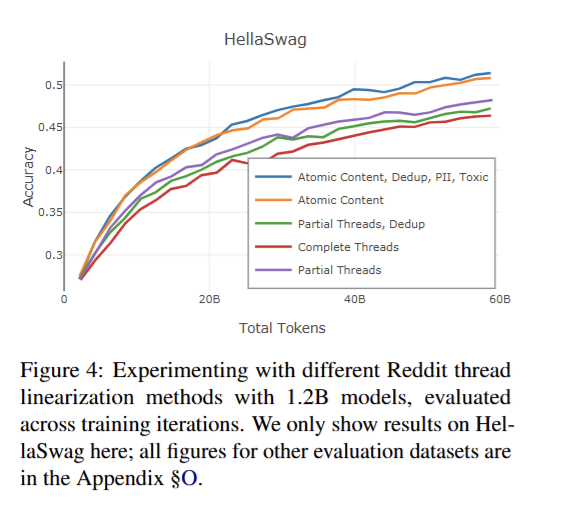 Hình 4: So sánh kết quả giữa các cách biểu diễn dữ liệu Social Media
Hình 4: So sánh kết quả giữa các cách biểu diễn dữ liệu Social Media
Quality Filtering
Đây là quá trình lọc bỏ các dữ liệu không đúng format, nhiễu; chuẩn hóa lại dữ liệu và trích xuất các dữ liệu cần thiết cho mục đích huấn luyện. Thông qua việc sử dụng các rules có sẵn, với từng loại dữ liệu, tác giả đã thử nghiệm như sau:
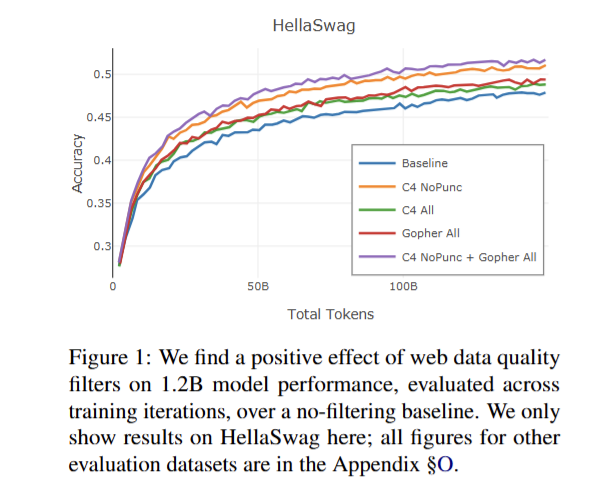 Hình 5: So sánh kết quả giữa các phương pháp xử lý quality dữ liệu web
Hình 5: So sánh kết quả giữa các phương pháp xử lý quality dữ liệu web
Dữ liệu web : Nhóm tác giả thử nghiệm 2 phương pháp heuristic trước đó bao gồm (Gopher và C4 - đây là những phương pháp sử dụng các bộ luật được định trước để loại bỏ dữ liệu). Thông qua thử nghiệm, họ nhận thấy việc kết hợp toàn bộ các luật Gopher và sử dụng luật C4 NoPunc (xóa các đoạn văn bản không kết thúc bằng dấu chấm) đạt hiệu quả cao nhất.
Dữ liệu code : sử dụng các phương pháp heuristic từ bộ Red Pajama v1 và StarCoder, loại bỏ các file dữ liệu hoặc được sinh ra từ template, các file chứa nhiều dòng comment hoặc HTML. Các github repo có số lượng sao đánh giá ít cũng được loại bỏ, họ lựa chọn kết hợp 2 rule từ 2 bộ trên để có được kết quả cao nhất
Dữ liệu social : tương tự xử lý như dữ liệu web, nhưng loại bỏ các đoạn submission nhỏ hơn 400 kí tự và comment nhiều hơn 500 kí tự, đồng thời loại bỏ các document bị xóa bởi tác giả, có nội dung độc hại, ..
Content Filtering
Đây là bước lọc bỏ các loại nội dung độc hại, hoặc các loại nội dung nhạy cảm như (thông tin cá nhân, số tài khoản, ..) ra khỏi bộ dữ liệu. Điều này rất cần thiết để đảm bảo tính an toàn và bảo mật của mô hình trong khi huấn luyện và sử dụng thực tế. Các loại dữ liệu đều được nhóm tác giả sử dụng cùng 1 phương pháp xử lý và được phân chia thành 2 phần chính như sau:
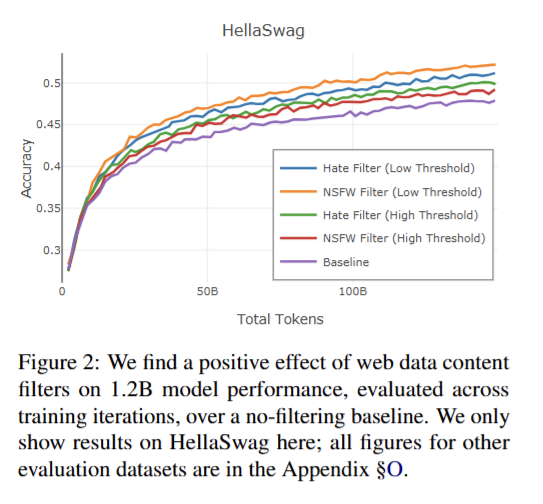 Hình 6: So sánh kết quả giữa các phương pháp lọc dữ liệu độc hại
Hình 6: So sánh kết quả giữa các phương pháp lọc dữ liệu độc hại
Lọc dữ liệu độc hại : họ huấn luyện mô hình FastText trên bộ JigSaw Toxic Comment (50K comments với các nhãn “toxic”, “severe toxic”, “threat”, “insult”, “obscene”) nhằm tạo ra hai mô hình phân loại “hate” (các comment không nhãn và “obscene” là negatives) và “NSFW” (comment có tag “obscene” là positive ). Họ nhận thấy sự trade-off giữa việc chọn threshold của mô hình (threshold lớn => dữ liệu mất di ít nhưng có hiệu quả thấp)
Lọc dữ liệu thông tin cá nhân: vì lượng dữ liệu lớn, nhóm tác giả sử dụng rule loại bỏ 3 kiểu dữ liệu chính (tài khoản email, số điện thoại và địa chỉ IP) thông qua dùng regular expression. Họ loại bỏ các document có nhiều hơn 5 kiểu dữ liệu trên hoặc sử dụng các special token thay thế cho chúng.
Deduplication
Đây là bước loại bỏ các dữ liệu có nội dung trùng lặp
- Dữ liệu web và social : thực hiện 3 stage bao gồm : lọc các url trùng nhau, lọc các document trùng nhau trong url trùng nhau, lọc các đoạn trùng nhau trong các document trùng nhau.
- Dữ liệu code : sử dụng phiên bản dữ liệu đã được loại bỏ trùng của Stack (cài đặt thuật toán MinHash và Locally Sensitive Hashing)
Thử nghiệm
Trong phần này, sau khi đã xây dựng được một quy trình xử lý dữ liệu hoàn thiện, mục tiêu của nhóm tác giả là đánh giá khả năng của pretrained khi huấn luyện trên bộ dữ liệu này so với các pretrained khác có hiệu quả như thế nào? Đồng thời so sánh hiệu quả của mô hình khi huấn luyện trên nhiều tập dữ liệu khác nhau thông qua phương pháp Paloma
Đánh giá mô hình OLMo-1B
Nhóm tác giả thực hiện huấn luyện mô hình OLMo (1.2B) với bộ dữ liệu trên so với các mô hình pretrained có cùng kích thước, ở một số các benchmark khác nhau. Kết quả cho thấy, OLMo outperform các mô hình có số lượng tham số tương đương và chỉ kém hơn so với StableLLM (1.6B). Các benchmark trên đều được đánh giá thông qua zero-shot - tương đối khó với các mô hình size nhỏ, tuy nhiên kết quả đều lớn hơn mức random (50%)
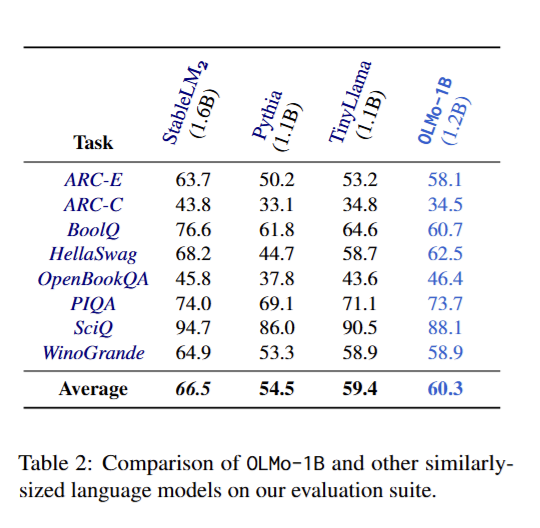 Hình 7: So sánh kết quả của OLMo với các mô hình pretrained cùng size trên một số task zero-shot
Hình 7: So sánh kết quả của OLMo với các mô hình pretrained cùng size trên một số task zero-shot
Đánh giá trên các miền dữ liệu
Trong phần này, nhóm tác giả sử dụng Paloma - một metrics đánh gía sự phù hợp của LLm trên các miền dữ liệu khác nhau thông qua perplexity. Họ huấn luyện mô hình 1.2B (OLMo) trên nhiều bộ dữ liệu khác nhau : C4, mC4 (English-only) , RedPajama v1, RefinedWeb Pile, and Dolma.
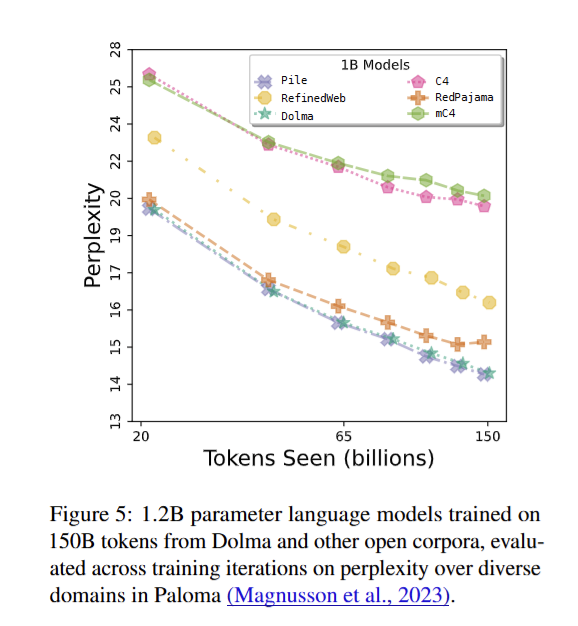 Hình 8: So sánh kết quả của Paloma trên các bộ dữ liệu khác nhau khi cùng huấn luyện trên mô hình OLMo 1.2B
Hình 8: So sánh kết quả của Paloma trên các bộ dữ liệu khác nhau khi cùng huấn luyện trên mô hình OLMo 1.2B
Có thể thấy, các mô hình được huấn luyện từ một nguồn (C4, mC4, RefineWeb) đều có kết quả perplexity cao. Ngược lại, mô hình huấn luyện trên Pile có kết quả tốt nhất mặc dù có kích thước nhỏ hơn nhiều, đồng thời dữ liệu đến từ nhiều nguồn như Dolma và RedPajama v1 có kết quả gần tương đương với Pile. Điều khiến mô hình trên Pile có hiệu quả tốt nhất là do nó có kích thước nhỏ và đựa lựa chọn kĩ lưỡng, nhưng dù kích thước dữ liệu lớn hơn rất nhiều (dữ liệu web - khó kiểm soát hơn), nhưng mô hình trên Dolma có kết quả tương đương.
Tổng kết
Trong bài báo này, đầu tiên, nó giúp mình có một hình dung cụ thể hơn về quá trình xây dựng một bộ dữ liệu pretraining cho LLM, hiểu kĩ hơn từng bước thực hiện - thứ mà mình thường hay bỏ qua. Đồng thời, tác giả cũng giới thiệu quy trình đánh giá cũng như cách thức lựa chọn phương pháp xử lý dữ liệu nhằm tối ưu khả năng của LLM và công bố bộ dữ liệu và tool khá hữu ích, thúc đẩy tính minh bạch trong quá trình huấn luyện mô hình ngôn ngữ.