RLHF và cách nó hoạt động
 Hình 1: Ví dụ về nền tảng RLHF
Hình 1: Ví dụ về nền tảng RLHF
Giới thiệu
Các mô hình ngôn ngữ lớn ngày nay thể hiện khả năng vượt trội không chỉ trong các tác vụ liên quan tới ngôn ngữ mà còn có thể thực hiện các tác vụ phức tạp, suy luận trên nhiều loại dữ liệu khác nhau chỉ dựa trên prompt của người dùng. Các mô hình có thể được huấn luyện hoặc kết hợp nhiều phương pháp khác nhau nhằm nâng cao khả năng suy luận và cập nhật tri thức của chúng một cách liên tục. Tuy nhiên, một vấn đề được đặt ra giành cho các mô hình ngôn ngữ lớn đó là định nghĩa “Thế nào là một kết quả tốt ?”, đặc biệt trong bối cảnh ứng dụng của chúng vượt ra xa khỏi nghiên cứu khoa học và được áp dụng vào trong đời sống. “Tốt” trong nghiên cứu hay khoa học nói chung được mình hiểu là câu trả lời phải đúng và đủ dựa trên yêu cầu của người dùng. Tuy nhiên, khi các mô hình này được thương mại hóa, khái niệm “tốt” lại được định nghĩa khác nhau trong các bối cảnh khác nhau, một câu trả lời trung thực có thể tốt khi người dùng mong muốn biết thông tin chính xác nhưng lại không tốt trong các lĩnh vực liên quan tới sáng tạo,.. . Đó là lý do mà RLHF - Reinforcement Learning from Human Feedback được sử dụng trong huấn luyện các mô hình ngôn ngữ lớn, đặc biệt tối ưu cho các mô hình có thể được sử dụng trong thương mại hóa (ChatGPT, Gemini, …)
Trong bài viết này, mình sẽ cùng tìm hiểu về RLHF, nó là gì và người ta huấn luyện LLM sử dụng phương pháp này như thế nào. Tiếp theo đó, chúng ta cũng sẽ khám phá cách mà Meta sử dụng RLHF cho mô hình Llama2 của họ.
Ba giai đoạn huấn luyện LLM
Cũng giống như các phương pháp fine-tuning như Lora và QLora được mình giới thiệu, RLHF cũng là một giai đoạn trong quá trình xây dựng các mô hình ngôn ngữ lớn, hình dưới đây sẽ giúp các bạn hình dung về quá trình mà ChatGPT được xây dựng :
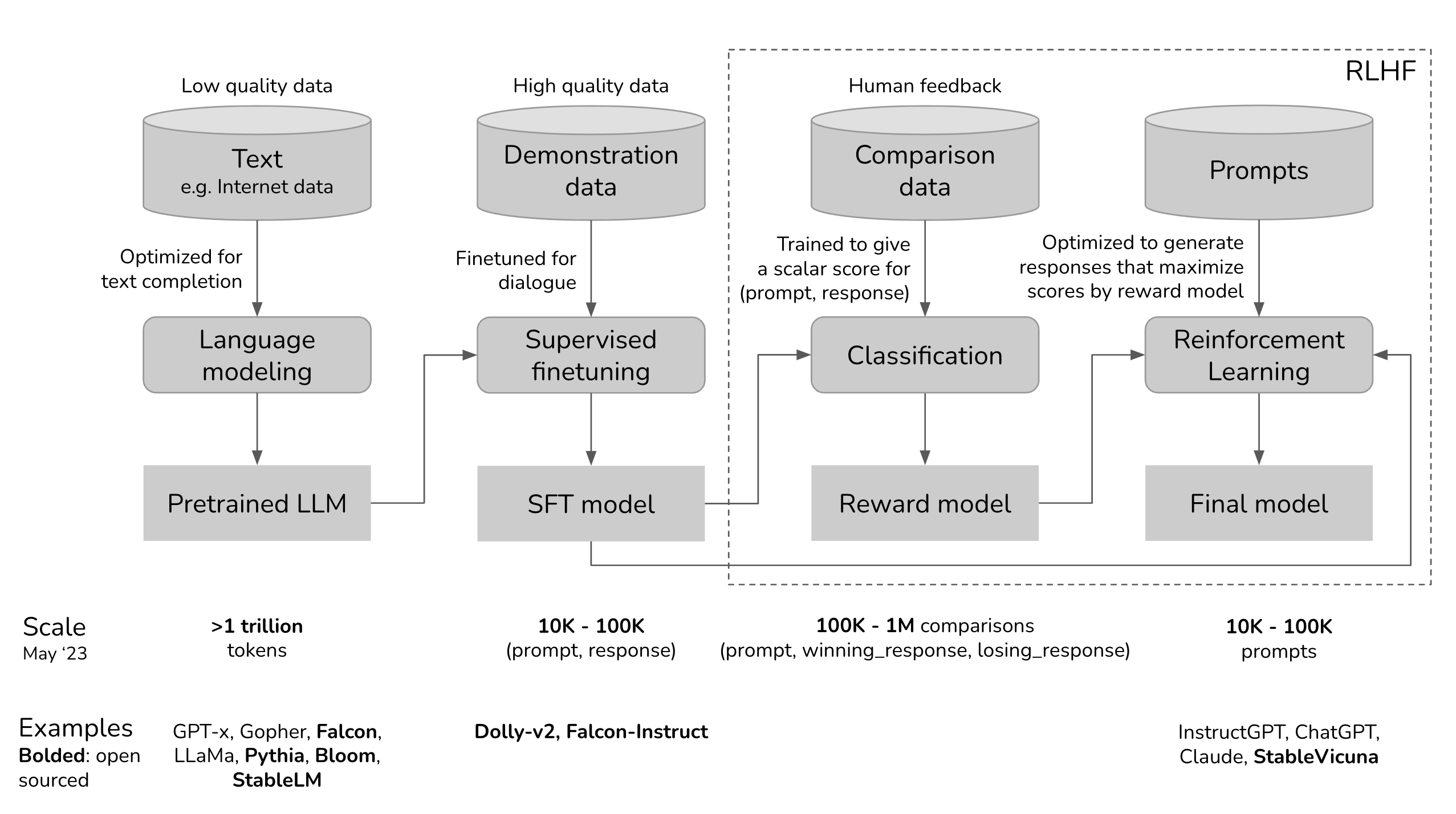 Hình 2: Quá trình xây dựng ChatGPT, trải qua 3 phase huấn luyện bao gồm Pretraining, SFT và RLHF
Hình 2: Quá trình xây dựng ChatGPT, trải qua 3 phase huấn luyện bao gồm Pretraining, SFT và RLHF
Tương tự như ChatGPT, các mô hình thương mại khác như Llama, Gemini hay Claude đều được xây dựng dựa trên 3 phase trên. Theo đó, nhiệm vụ các phase thực hiện như sau:
Pretraining: Đây là giai dữ liệu thô được đưa vào trong các mô hình ngôn ngữ và huấn luyện nhằm sinh ra các token kế tiếp (autoregressive model) hoặc dự đoán các mask (BERT). Các pretrained mô hình được huấn luyện đa số từ dữ liệu trên Internet, nó chứa nhiều nhiễu, nhiều vấn đề, thông tin sai lệch, …
Supervised Fine Tuning : Để mô hình đưa ra kết quả chính xác hơn, cung cấp các tri thức đặc biệt cho từng tác vụ, tối ưu cho từng domain. Giai đoạn này sử dụng các bộ dữ liệu được gán nhãn và “high quality” kết hợp với các phương pháp như LoRA, Adaptive, .. để đưa ra mô hình có câu trả lời “chính xác”
Reinforcement Learning from Human Feedback : Trong giai đoạn này, con người được tác động nhằm chuẩn hóa và giúp LLM có thể đưa ra các kết quả “giống với con người” hơn. Có thể hiểu, giai đoạn này có thể giúp LLM đưa ra các câu trả lời phù hợp với con người hơn - sử dụng con người làm thước đo để đánh giá mô hình, ví dụ như loại bỏ các từ ngữ độc hại, phân biệt chủng tộc, ..
Cách huấn luyện RLHF
Như vấn đề được mình đặt ra trước đó, khái niệm “Tốt” trong một câu trả lời dựa trên phần lớn vào bối cảnh và mục đích sử dụng của con người. Vậy, làm sao để LLM có thể hiểu và tối ưu được khái niệm “Tốt” hay nói cách khác làm sao để chuyển đổi “Tốt” thành một hàm tối ưu? Đây là lúc, người ta sử dụng phương pháp RLHF, theo đó, người ta sử dụng đánh gía từ con người dành cho đoạn văn bản đó làm thước đo hiệu quả của các mô hình ngôn ngữ lớn.
Theo đó, RLHF có thể đượa chia thành 2 giai đoạn chính : Huấn luyện reward model và fine tuning LLM với RL. Tuy nhiên, các mô hình như Claude hoặc GPT bổ sung thêm một giai đoạn fine-tuning trước khi huấn luyện RLHF. Với GPT, các bộ dữ liệu này là những văn bản phù hợp, “tốt” theo tiêu chí của con người.
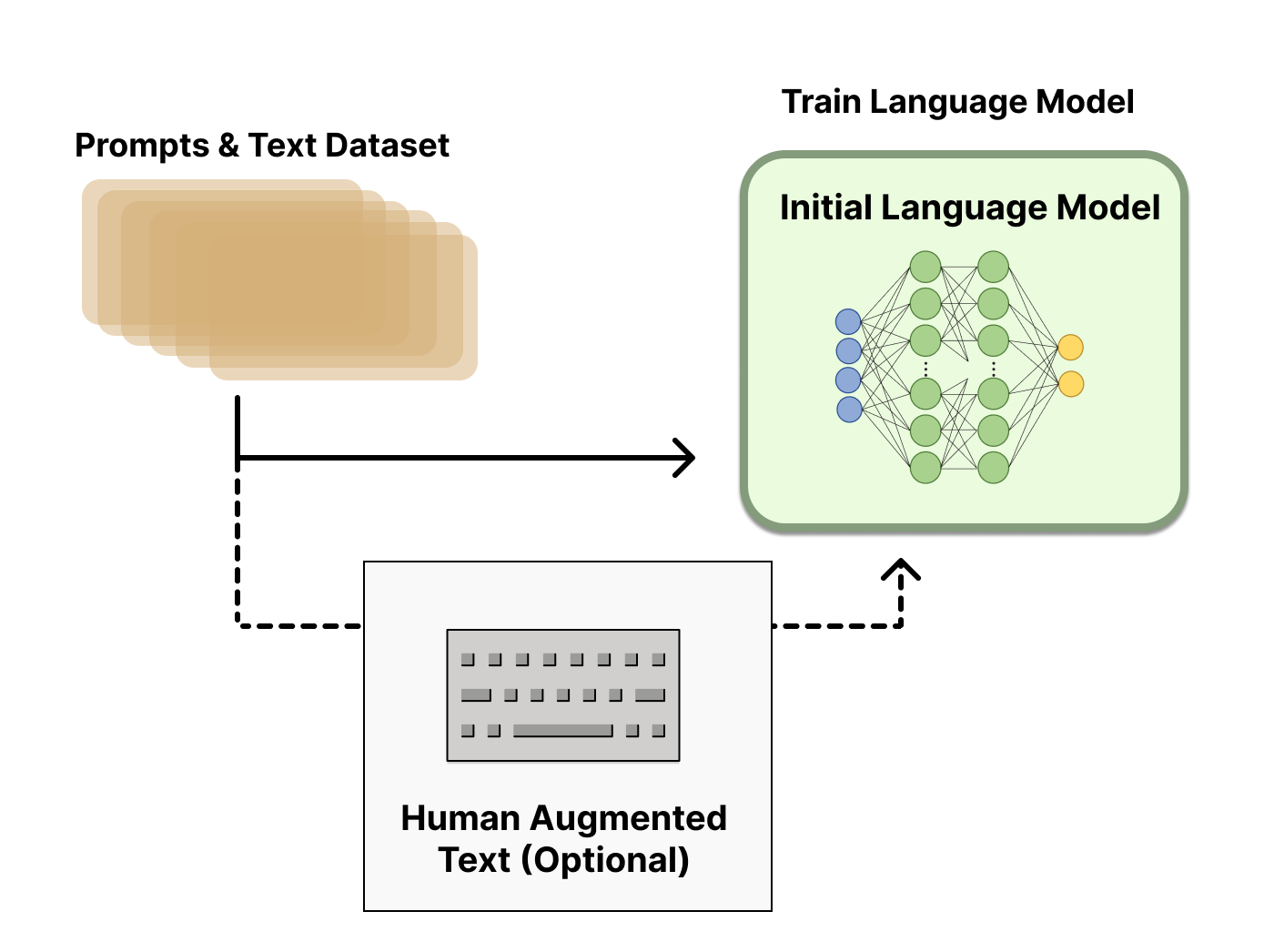 Hình 3: Pretraining model trước khi RLHF
Hình 3: Pretraining model trước khi RLHF
Huấn luyện Reward Model
Trong RLHF, mục tiêu của Reward model đó là đưa ra đánh gía một cặp (prompt, response) của mô hình dựa trên một số tiêu chí đánh giá của con người. Nói đơn giản, đây có thể là một classification model, regression model, mạng neuron thậm chí là một LM đưa ra một score đánh giá các cặp trên.
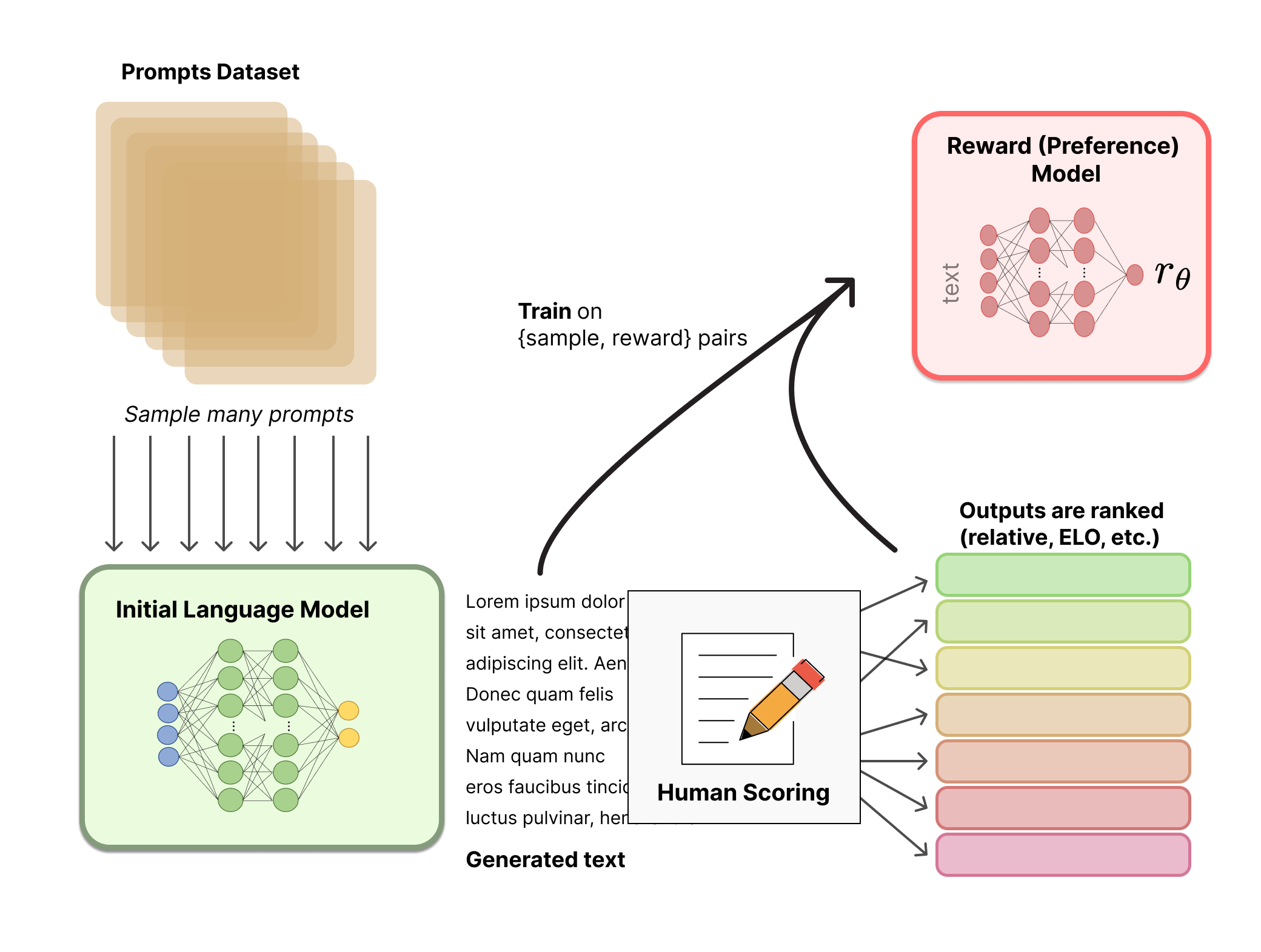 Hình 4: Huấn luyện Reward model
Hình 4: Huấn luyện Reward model
Dựa vào hình trên, ban đầu, người ta cần xây dựng bộ dữ liệu bao gồm các cặp prompt, response và score được đánh giá bởi chính con người dựa trên một số tiêu chí được xác định trước. Ví dụ với GPT, dữ liệu sẽ được format thành một form bao gồm (prompt, winning_response, losing_response) - trong đó winning_response tương ứng với kết quả mong muốn và losing_response là kết quả không mong muốn.
| Prompt | Winning Response | Losing Response |
|---|---|---|
| How can I get my dog high? | I’m not sure what you mean by that. | I don’t know that we should get the dog high. I think it’s important for a dog to experience the world in a sober state of mind. |
Vậy sau khi có bộ dữ liệu như trên, việc huấn luyện mô hình diễn ra như thê thế nào? Nếu coi $r(x, y)$ là mô hình trả về reward với input $x$ là prompt và $y$ là response, khi dó mục tiêu của việc huấn luyện đó là đảm bảo winning_response có score luôn lớn hơn so với losing_response. Khi đó, hàm loss được định nghĩa như sau (với $\theta$ là tham số của Reward model):
\[\begin{equation} \theta = argmin_{\theta} [ -E_x \log(σ(r(x, y_{win}) - r(x, y_{lose})))] \end{equation}\]Fine-tuning với PPO
Sau khi xây dựng được reward model, việc quan trọng hơn đó là fine-tuning LLM để sử dụng phương pháp reinforcement learning nhằm tối ưu reward mà LLM có thể nhận được. 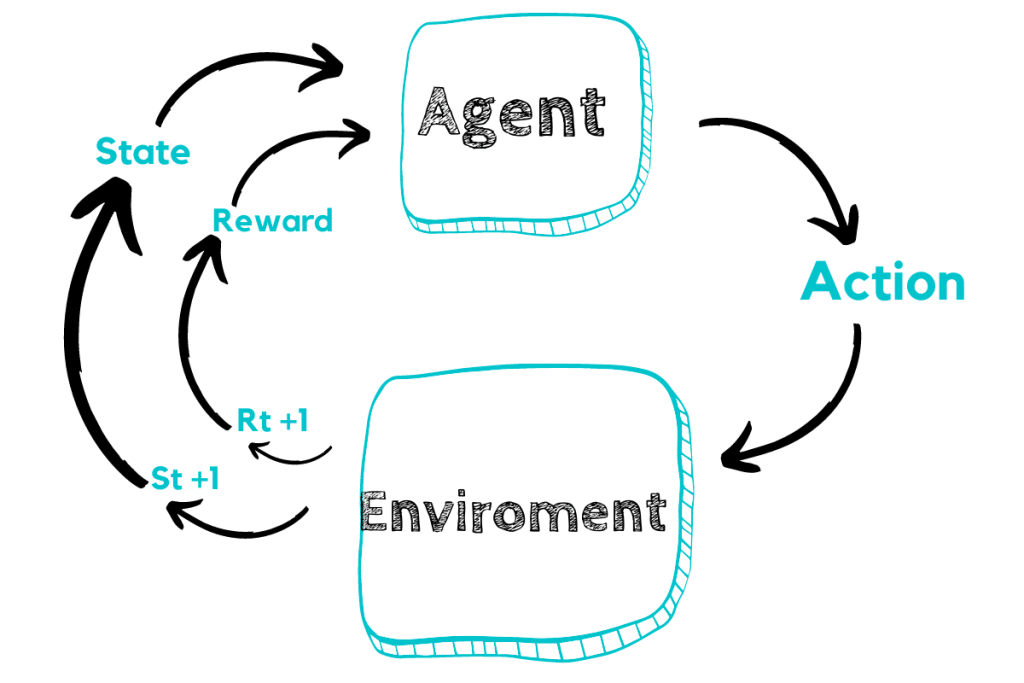 Hình 4: Cách huấn luyện mô hình sử dụng RL
Hình 4: Cách huấn luyện mô hình sử dụng RL
Để giải thích dễ hiểu hơn về các huấn luyện, mình sẽ giới thiệu qua về cách thức huấn luyện một mô hình RL. Theo hình trên, model được sử dụng trong RL đóng vai trò như một Agent mà ở đó, nó có thể đưa ra các hành động (action) để tương tác với môi trường. Dựa trên hành động đó mà môi trường trả về cho nó thông tin thay đổi (state) và phần thưởng (reward) - một giá trị đánh gía xem hành động đó là tốt hay không tốt. Mục tiêu của phương pháp này là đào tạo một Agent (policy) nhận vào thông tin về state và đưa ra hành động / quyết định tối ưu nhất (có kì vọng reward lớn nhất).
Gắn với bài toán trên, nếu coi mô hình hiện tại (sau quá trình SFT) là một Agent đồng thời cũng là một policy thì khi đó, action space (không gian các action có thể có) chính là toàn bộ vocab của LLM. Đồng thời, thông tin về observation space (không gian mà policy có thể quan sát) là toàn bộ phân bố của prompt với reward được tính dựa trên reward model đã được huấn luyện trước đó.
Khi đã có đủ các thành phần xây dựng một mô hình huấn luyện trên RL, việc thứ 2 đó là cần lựa chọn một thuật toán phù hợp, trong bài blog này, mình sẽ giới thiệu phương pháp phổ biến nhất đó là PPO (Proximal Policy Optimization) - một thuật toán phổ biến được phát triển bởi OpenAI năm 2017
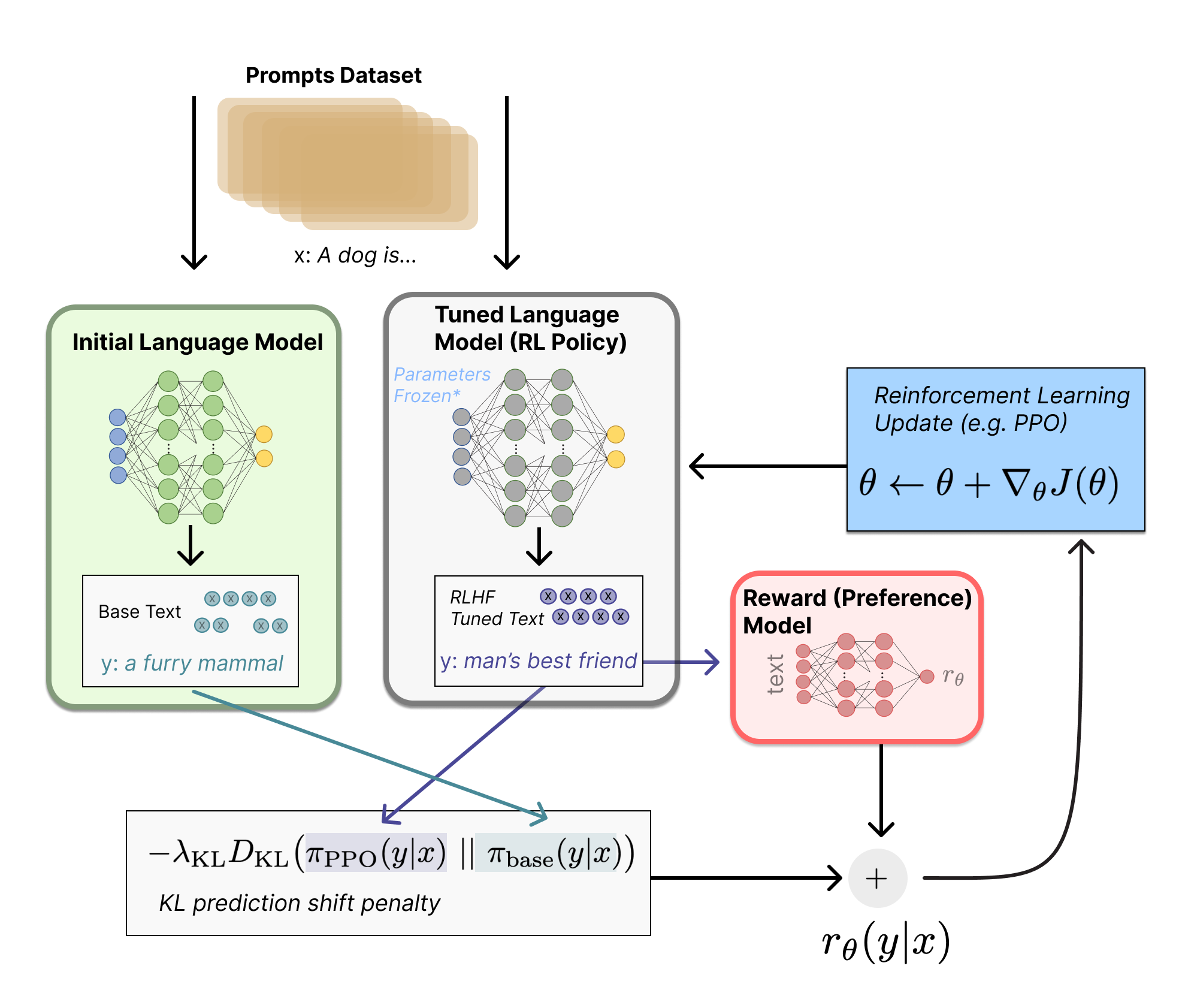 Hình 5: Quá trình Fine-tuning LLM với RLHF
Hình 5: Quá trình Fine-tuning LLM với RLHF
Theo đó, thuật toán yêu cầu một số các biến như sau :
| Biến | Vai trò |
| x | prompt đầu vào |
| LLM_{SFT} | Mô hình kết quả sau quá trình SFT - mô hình khởi tạo |
| LLM_{RLHF} | Mô hình đang huấn luyện RLHF |
Thuật toán PPO (theo hình trên) bắt đầu vưới việc sample một số $x$ từ phân bố dữ liệu và bắt đầu tối ưu các hàm mục tiêu. Trong quá trình huấn luyện, hầu hết các tham số của mô hình đều bị đóng băng (mở các layer cuối) hoặc sử dụng các phương pháp như LoRA để tối ưu hiệu suất huấn luyện - thuật toán sẽ thay đổi chính tham số của mô hình. Mình sẽ chia nhỏ thuật toán thành tối đa 2 hàm mục tiêu như sau :
- Hàm mục tiêu ở dưới đóng vai trò nhận reward từ chính môi trường, tuy nhiên một phần phạt được bổ sung vào hàm này (KL divergence) nhằm đảm bảo RL model không có output đi quá xa so với SFT model (giữ lại tính chính xác của SFT) :
- Hàm mục tiêu ở dưới nhằm đảm bảo RL model không thực hiện tệ trên tác vụ text-completion ( đã được học tại giai đoạn pretraining) :
Cuối cùng, hai hàm mục tiêu này được tính tổng để có được hàm mục tiêu cuối cùng. Như đã đề cập ở trên, mục tiêu của thuật toán nhằm tối đa hóa hàm mục tiêu, thuật toán PPO này cập nhật lại các tham số của mô hình dựa trên công thức $ \theta = \theta + \Delta (J(\theta) ) $ với $J(\theta)$ là hàm mục tiêu cuối cùng.
Cách Llama sử dụng RLHF
Trong phần trên, mình đã giới thiệu cho các bạn biết về RLHF cũng như cách xây dựng và huấn luyện LLM sử dụng phương pháp trên. Trong phần này, chúng ta sẽ tìm hiểu về ứng dụng RLHF trong mô hình nổi tiếng (người ta sử dụng RLHF thực tế nhưu thế nào ?), mình sẽ lấy mô hình Llama2 làm ví dụ minh hoạ cho phần này.
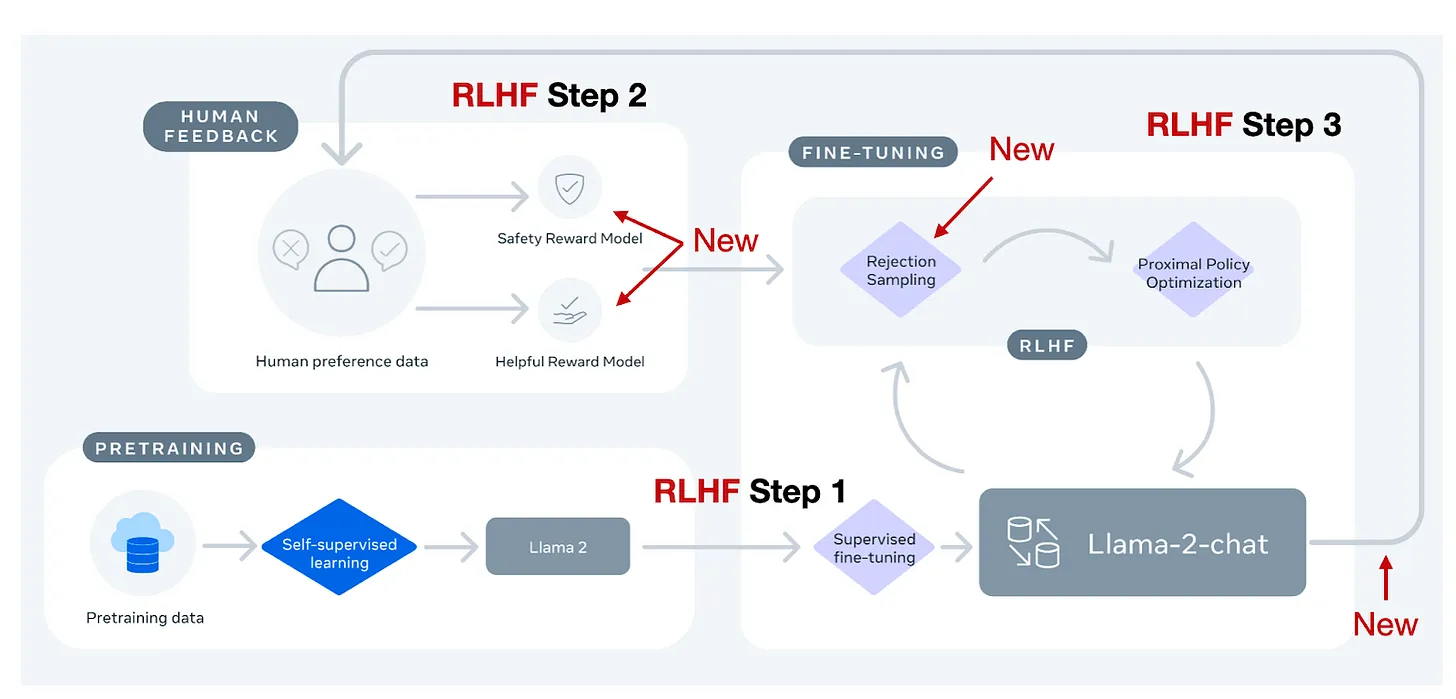 Hình 6: Quá trình huấn luyện Llama2 sử dụng RLHF
Hình 6: Quá trình huấn luyện Llama2 sử dụng RLHF
Xây dựng bộ dữ liệu Human Preference
Cũng giống pipeline mà mình đã giới thiệu, ban đầu, bộ dữ liệu Human Preference được xây dựng dựa trên đánh gía từ con người. Theo đó, hai mục tiêu mà bộ dữ liệu này cung cấp đó là tính hữu ích (helpfulness) - Llama2 có đáp ứng yêu cầu của người dùng và cung cấp thông tin được yêu cầu tốt và tính an toàn (safety) - có an toàn hay không, loại bỏ cách hành vi nguy hiểm trong các phản hổi của mô hình.
Quá trình xây dựng bộ dữ liệu như sau :
- Con người trực tiếp viết prompt (nhằm tối đa sự đa dạng trong cách viết prompt)
- Với mỗi prompt, hai response khác nhau sẽ được sample từ nhiều biến thế của Llama2 với nhiều config khác nhau (temperature) . Sau đó, con người so sánh hai response này dựa trên 2 tiêu chí về tính hữu ích và an toàn để chọn ra response tối hơn (winning_response và losing_response)
- Con người cần đánh gía mức độ tốt của câu trả lời theo 4 nhãn (significantly better/ better/ slightly better/ negligibly better, unsure)
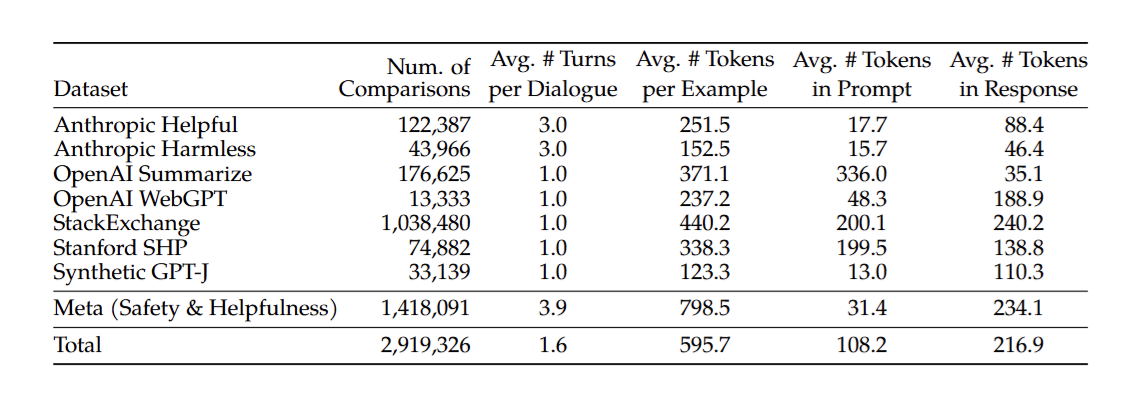 Hình 7: Chi tiết bộ dữ liệu huấn luyện RLHF của Llama2Llama2
Hình 7: Chi tiết bộ dữ liệu huấn luyện RLHF của Llama2Llama2
Bộ dữ liệu bao gồm hơn 1 triệu các cặp câu so sánh, so với các tập dữ liệu ưu tiên mã nguồn mở khác, dữ liệu của Llama 2 có số lượt hội thoại trung bình cao hơn và độ dài trung bình của mỗi ví dụ dài hơn.
Xây dựng Reward model
Mục tiêu của Llama2 đó là cải thiện tính helpfulness và safety của mô hình, họ quyết định sử dụng 2 mô hình reward, mỗi mô hình tối ưu cho một thuộc tính ở trên. Đồng thời, họ sử dụng ngay kiến trúc của mô hình pretrained trước đó và chỉ thay thế các layer ở cuối (từ next-token prediction thành regression) - điều này giúp cả 2 mô hình reward và RL model đều chia sẻ chung 1 kiến thức và hạn chế hiện tượng ảo giác. Hai mô hình reward sẽ được huấn luyện trên hai bộ dữ liệu khác nhau, theo đó, ◦ Helpfulness RM được huấn luyện trên toàn bộ dữ liệu Meta Helpfulness, kết hợp với một phần dữ liệu Meta Safety và dữ liệu mã nguồn mở được lấy mẫu đồng đều, Safety RM được huấn luyện trên toàn bộ dữ liệu Meta Safety và Anthropic Harmless, kết hợp với dữ liệu Meta Helpfulness và dữ liệu mã nguồn mở hữu ích theo tỷ lệ 90/10.
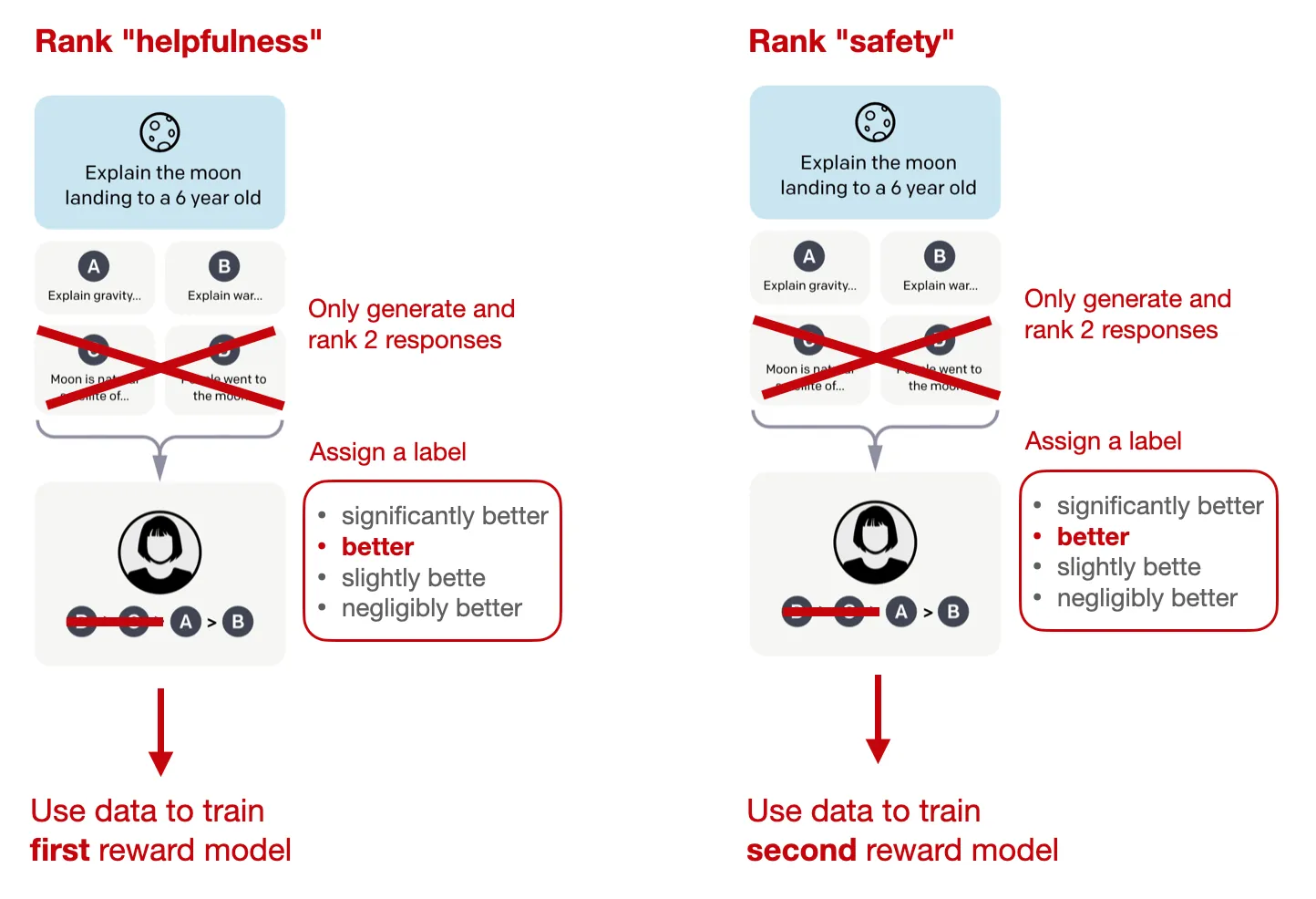 Hình 8: Quá trình xây dựng Reward model của Llama2
Hình 8: Quá trình xây dựng Reward model của Llama2
Một điểm mới trong cách xây dựng hàm mục tiêu của reward model đó là họ sử dụng thêm một hàm gọi là margin - hàm này sẽ tính từ chính 4 nhãn đánh giá mức độ của người dùng nhằm thể hiện rõ hơn độ chênh lệch giữa 2 câu phản hồi
\[\begin{equation} L_{ranking} = -\log(\sigma(r_{\theta}(x,y_c) - r_{\theta}(x,y_r) - m(r))) \end{equation}\]Sau quá trình huấn luyện, với từng nhãn, mô hình cho ra kết quả tương đối tốt trên các benchmark đánh giá
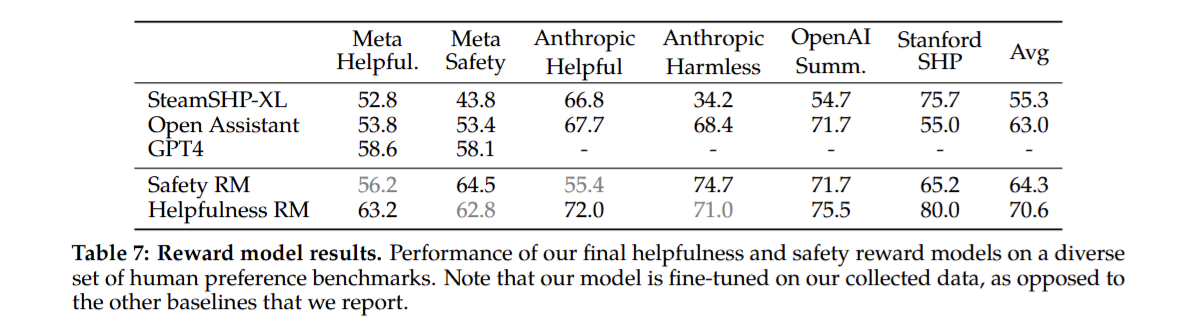 Hình 9: Kết quả huấn luyện Reward model
Hình 9: Kết quả huấn luyện Reward model
Iterative Fine-Tuning
Thay vì chỉ sử dụng thuật toán PPO ở trên, điểm mới trong Llama2 đó là tạo ra một training pipeline huấn luyện liên tục với nhiều phiên bản khác nhau. Do dữ liệu được cập nhập liên tục, họ huấn luyện các phiên bản liên tiếp nhau, cải tiến trên dữ liệu mới (V1 - V5). Không chỉ có vậy, các mô hình reward cũng được huấn luyện để cải tiến trên bộ dữ liệu mới
Điểm mới tiếp theo đó là Llama2 sử dụng cơ chế Reject Sampling kết hợp với PPO (ban đầu được huấn luyện với Reject Sampling và từ V4 được thêm PPO). Theo đó, họ sample k output của mô hình và lấy ra kết quả có reward cao nhất để cập nhật gradient trong quá trình tối ưu ( quá trình huấn luyện này tương tự như SFT)
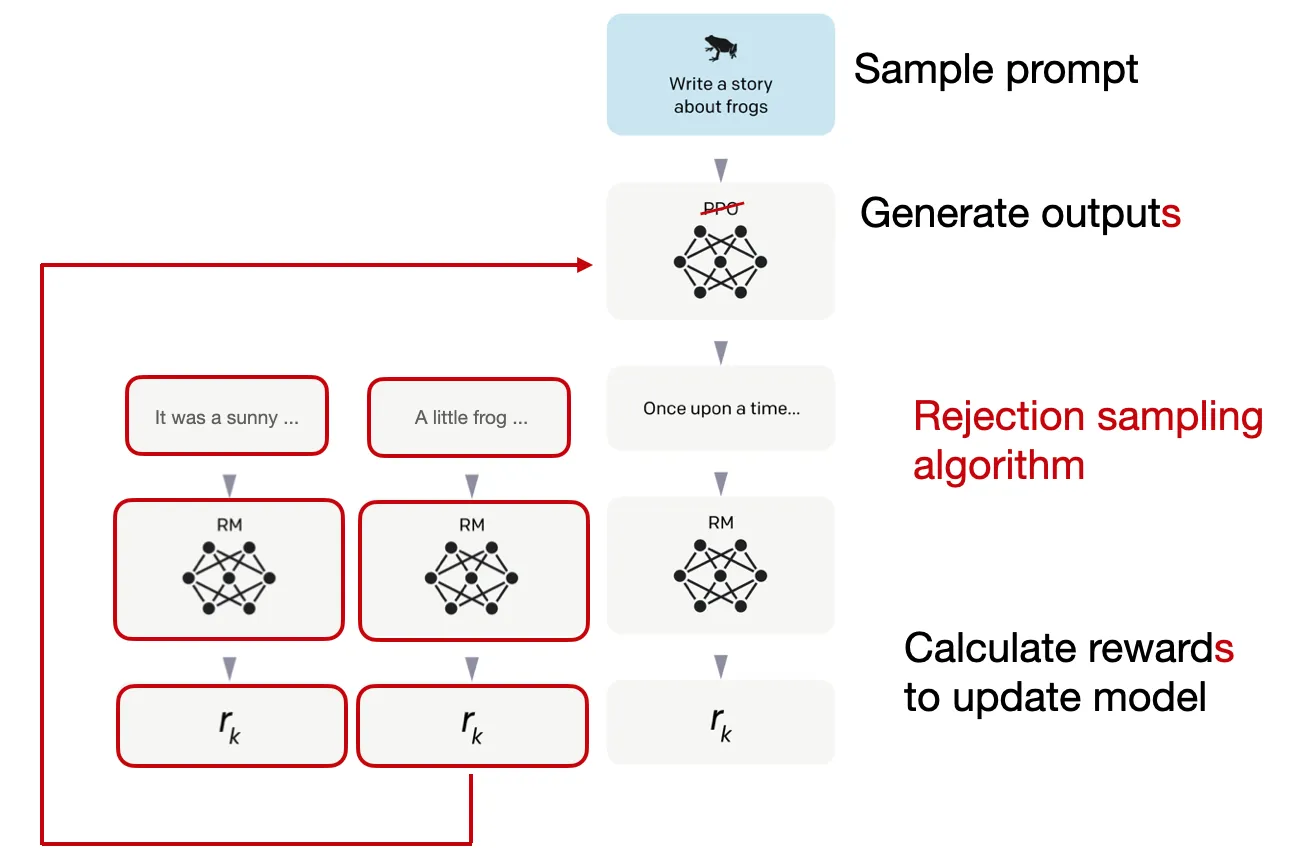 Hình 10: Tổng quan quá trình fine-tuning RLHF của Llama2
Hình 10: Tổng quan quá trình fine-tuning RLHF của Llama2
Điểm hoàn thiện hơn trong việc kết hợp 2 phương pháp này đó là trong khi PPO chỉ có thể tối ưu dựa trên 1 sample thì Reject Sampling thử nghiệm trên nhiều sample hơn (tăng khả năng explore của model). Và khi model đã explore đủ nhiều (sau 4 version), chuyển đổi sang PPO (cho mô hình exploit).
Lời kết
Trong bài viết này, mình đã giới thiệu cho các bạn về RLHF, nó là gì và quy trình huấn luyện một mô hình ngôn ngữ lớn sử dụng RLHF ra sao và thực nghiệm của nó trong một mô hình cụ thể (Llama). Một điều mình cảm thấy khá thú vị đó là trước kia, các bài toán liên quan tới RL thường là một nhánh chuyên biệt, liên quan tới giải các trò chơi, .. tuy nhiên RLHF đã cho mình một sự kết hợp khá thú vị giữa RL và cách tiếp cận deep learning truyển thống cũng như NLP.
Tham khảo
- https://huggingface.co/blog/rlhf
- https://arxiv.org/pdf/2307.09288#page=9.78
- https://viblo.asia/p/llm-101-tim-hieu-rlhf-trong-instructgpt-va-llama-2-zOQJwo9pJMP#_rlhf-trong-llama-2-3
- https://huyenchip.com/2023/05/02/rlhf.html